27 октября в Яндексе проходила тренировка по машинному обучению на основе HR данных - задание по прогнозу повышения работника. Спикеры показывали свое решение по участию в конкурсе WNS Analytics Wizard 2018 о прогнозированию повышения работников, в котором они заняли второе место.

Я бы хотел рассказать о самом задании и тех уроках, что HR могут извлечь для себя. Данные представляли из себя следующее:
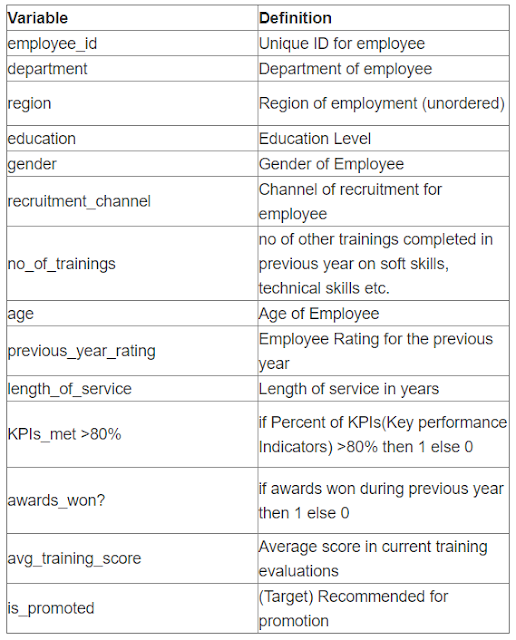
Последняя переменная - целевая, ее надо было предсказывать - она состоит из значения 0 или 1 - имел работник повышение по службе или нет. Про остальные переменные могу сказать ровно столько, сколько в таблице (к сожалению, организаторы конкурса по словам участников очень жестко следят за тем, чтобы данные не выходили наружу, поэтому я не смог достать сами данные). Особенно интересно узнать, что такое avg_training_score - что за баллы получают работники в ходе обучения в компании?
Я бы хотел рассказать о самом задании и тех уроках, что HR могут извлечь для себя. Данные представляли из себя следующее:


0 50140
1 4668
4 668 работников получили карьерное повышение, т.е. 8, 5 % получили карьерное повышение. Таким образом нам надо понять, какие факторы / переменные влияют на карьерное повышение и построить модель прогноза карьерного повышения.
Точность модели

В абсолютных значениях это будет выглядеть так
реальные значения
|
не получил повышения
|
49137.2
|
1002.8
|
получил повышение
|
2520.72
|
2147.28
|
|
не получил повышения
|
получил повышение
|
||
прогнозные
|
|||
Т.е. точность precision модели = 68 %. Не так плохо на таких данных.
Уроки для HR
Если кто-то из HR дочитал до этого момента, то, надеюсь, вам это будет полезным. Решение, которое представили Дмитрий Симаков и Никита Чуркин, заняло второе место в конкурсе. Акцентирую внимание, чтобы показать, за чет чего они достигли результата.А результат был достигнут, в первую очередь, за счет создания новых переменных, в первую очередь - агрегации сырых данных. Самый простой пример - когда мы в модели пол подчиненного объединяем с полом руководителя Гендер руководителя и подчиненного: кто от кого уходит быстрее или более сложный вариант Как сочетание психотипов руководитель - подчиненный влияет на эффективность подчиненных - я кластеризовал результаты тестов руководителя и подчиненного и сметчил их, фактически показав, как интеракция психотипов связана с эффективностью.
Так вот, в модели прогнозирования повышения работников основную точность добавили агрегированные переменные.
Я запомнил одну из: отличие avg_training_score работника от среднего по департаменту. Т.е. переменная получается так: мы считаем среднее по департаменту, а потом считаем разницу между этим средним и собственно результатом работника. Согласитесь, что в целом очень логично: взять не просто среднее, а среднее по своему департаменту? И таких переменных было создано десятки (напомню, что в самой модели было всего 12 сырых переменных!).
Нелогично здесь следующее: Дмитрий Симаков и Никита Чуркин не HR! Они не обладают экспертизой в HR (достаточно сказать, что на презентации решения во время рассказа о переменных они признались, что не знают, что такое recriutment_channel. Но они и не должны знать, что это важный показатель в HR Анализ источников трафика (каналов привлечения) кандидатов, они не HR, про это должны знать мы, HR эксперты). Но они додумались до этой переменной.
А теперь представьте, что это не ситуация конкурса. И ваши спецы по анализу данных не уровня упомянутых коллег. Да и мотивации у них на победу нет особенно. Да и чуйки нет особой. Они бы слепили модель и получили что-то среднее ....
Джош Берзин указывал, что в команде HR-аналитиков в компании должен быть обязательно HR-эксперт см. Рост Talent Intelligence: HR-аналитика набирает скорость. Одна из функций HR-эксперта, на мой взгляд, в генерации гипотез, какие переменные должны быть. Да, технически спецы сами могут нарыть это. Но они далеко не всегда это будут делать, могут просто не захватить, а HR-эксперт должен генерить идеи, должен контролировать и проверять реализацию, но все это при одном важном условии: HR эксперт должен хорошо понимать, о чем рассказывают все диаграммы в в посте. Если вы понимаете, напрашивайтесь в команду HR-аналитиков и генерите идеи!
ПыСы
Если кому то интересны решения кейса с кодом в Python, то- How to save HR’s time with machine learning - решение Дениса Воротынцева
- Data Analytics and Modeling with XGBoost Classifier : WNS Hackathon Challenge - решение индуса, который занял 138 место
- WNS-Analytics-Wizard-2018-Machine-Learning-Hackathon-/wns_employee_promotion_model.ipynb - код на Гитхабе кого-то из участников по этой задаче
__________________________________________________________
На этом все, читайте нас в фейсбуке, телеграмме и вконтакте
Комментариев нет:
Отправить комментарий