Понятно, что я не охвачу все возможные варианты обработки вопросов с множественным выбором, но, надеюсь, хватит, чтобы самим дальше продвигаться.
Показываю на примере поста Популярность джоб сайтов среди соискателей / кандидатов.
У нас есть вопрос, на каких джоб сайтах, вы размещали резюме. Посмотрите это в самом опросе Исследование времени поиска работы (и пройдите его). Результат это вопроса записывается так
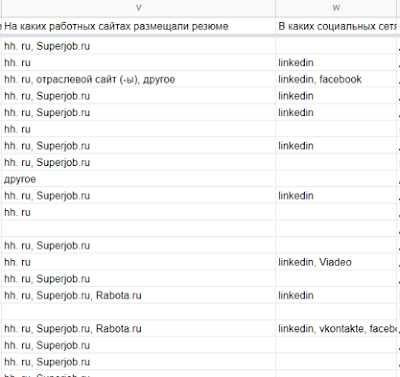
Захватил соседний вопрос, в каких социальных сетях, размещали резюме. Заметно, что результаты сохраняются одной ячейке, и это главное неудобство для обработки.
Т.е. если вы сравните с картинкой выше, вы обратите, что в колонке hh стоят везде единички, потому что hh.ru присутствует во всех первых пяти строках. Superjob содержит единички в тех ячейках, где этот сайт был выбран респондентом и т.п..
Такое преобразование позволяет уже пользоваться этими переменными при построении моделей, выявлении различий и т.п...
В R это делается так
Этой формулой мы создаем новую переменную. Буквально она звучит так: если у нас в ячейке содержится hh, то в новой переменной значение ячейки будет = 1, в остальных случаях = 0.Показываю на примере поста Популярность джоб сайтов среди соискателей / кандидатов.
У нас есть вопрос, на каких джоб сайтах, вы размещали резюме. Посмотрите это в самом опросе Исследование времени поиска работы (и пройдите его). Результат это вопроса записывается так

Захватил соседний вопрос, в каких социальных сетях, размещали резюме. Заметно, что результаты сохраняются одной ячейке, и это главное неудобство для обработки.
Преобразование в бинарные переменные
Покажу первые пять строк. После преобразования у нас первые пять строк принимают такой вид
hh
|
Superjob
|
Отраслевые
|
другое
|
1
|
1
|
0
|
0
|
1
|
0
|
0
|
0
|
1
|
0
|
1
|
1
|
1
|
1
|
0
|
0
|
1
|
1
|
0
|
0
|
Т.е. если вы сравните с картинкой выше, вы обратите, что в колонке hh стоят везде единички, потому что hh.ru присутствует во всех первых пяти строках. Superjob содержит единички в тех ячейках, где этот сайт был выбран респондентом и т.п..
Такое преобразование позволяет уже пользоваться этими переменными при построении моделей, выявлении различий и т.п...
В R это делается так
df$hh = ifelse(grepl('hh',df$На.каких.работных.сайтах.размещали.резюме), 1, 0)
Я показал только на примере одной переменной, понятно, что также надо делать с остальными.
Подсчет числа выборов
А если мы хотим посчитать, как часто выбирали респонденты HH, Superjob и т.п.?
И получить вот такую картинку

HH = grep("hh",df$На.каких.работных.сайтах.размещали.резюме,value=F)
HH = length(HH)/nrow(df)
Superjob = grep("Superjob",df$На.каких.работных.сайтах.размещали.резюме,value=F)
Superjob = length(Superjob)/nrow(df)
Первой строкой я считаю количество ячеек, содержащих hh, второй строкой я считаю % (делю на количество строк датасета). Если вам не нужны проценты, вы убираете знаменатель и все. Теперь у нас есть два объекта HH и Superjob, нам нужно получить диаграмму (на самом деле у вас будет больше объектов, по числу вариантов ответа, но я просто экономлю пространство, поскольку это просто повторение. И диаграмму я получаю так: объединяю объекты в один датасет js = data.frame(value = c(HH, Superjob, Rabota, job, Росработа, avito, otrasl))
col = c('HH', 'Superjob', 'Rabota', 'job', 'Росработа', 'avito', 'otrasl')
df = cbind(col, js)
И теперь визуализируем
df = df[order(-(df$value)),] # задаю в порядке убывания df library(ggplot2) ggplot(df,aes(x = reorder(df$col, df$value), y = df$value)) + geom_bar(stat="identity", fill="coral1", colour="darkgreen") + geom_text(aes(label=paste(round(df$value*100, 1),"%",sep="") ), hjust = 0.5, size=8) + theme(text = element_text(size=30), plot.title = element_text(hjust = .5)) + coord_flip()+ labs(title = "% респондентов", y = " ", x='сети')+ theme(axis.text = element_text(size = 19))Обратите внимание, я перед загрузкой диаграммы сначала расположил варианты ответа в порядке убывания.
Все, мы посчитали количество выбранных вариантов.
Сравнение групп
А если вы захотели посчитать, как пользователи разных джоб сайтов различаются с т.з. зарплаты, возрасте, уровня позиции и т.п.? Т.е. мы захотим получить, например, вот такую диаграмму
Т.е. мы сравниваем группы. Мы получили ранее отдельные бинарные переменные, которые позволяют сравнить, например, HH.RU с остальными сайтами сразу всеми вместе, но нам то нужно именно все сайты посмотреть, значим нам нужно получить такой датасет, в котором будут две колонки:
- принадлежность к сайту / группе, т.е. переменная будет состоять из значений 'hh', 'Superjob' и т.п..,
- зарплата
В R я делаю это так
q$hh = ifelse(grepl("hh",q$На.каких.работных.сайтах.размещали.резюме), '1', '0')
hh = q[q$hh == '1', ]
С помощью первой строки я повторяю, что делал выше - создаю новую переменную, а второй строкой фильтром отбираю только те строки полного датасета, где содержится HH. Далее я с помощью пакет dplyr отбираю зарплаты, создаю из них новый датасет hh, и в нем новую переменную js -она - эта переменная - состоит только из значений hh, т.е. мы выбрали зарплаты только тех респондентов, которые размещали свои резюме на HH.RU
library("plyr"); library("dplyr")
hh = select(hh, zp = Размер.зарплаты.на.момент.увольнения)
str(hh)
hh$js = 'hh'
Аналогично я проделываю это с другими сайтами: для Superjob создаю датасет Superjob и так далее
q$Superjob = ifelse(grepl("Superjob",q$На.каких.работных.сайтах.размещали.резюме), '1', '0')
Superjob = q[q$Superjob == '1', ]
Superjob = select(Superjob, zp = Размер.зарплаты.на.момент.увольнения)
str(Superjob)
Superjob$js = 'Superjob'
Теперь нам надо все это объединить в единый датасет. rbind() нам в помощь, поскольку названия переменных во всех датасетах у нас идентичные.
js = rbind(hh, Superjob, Rabota, otrasl ) js$zp = as.numeric(as.character(js$zp)) js$js = as.factor(js$js)Далее мы можем посмотреть значимость различий
kruskal.test(js$zp ~ js$js)Выяснив, что для наших данных таких различий нет. И построим боксплот
ggplot(js, aes(x=js, y=zp/1000, fill=js)) + geom_boxplot(color='blue') +
theme_grey(base_size = 30)+ theme(legend.position="none") +
scale_y_continuous(breaks=seq(0, 250, 25)) + coord_flip(ylim=c(0, 250)) +
ylab('зарплата')
Обратите внимание, что в формуле я использую zp/1000 - т.е. делю зарплату на 1000, чтобы деления не рябили нулями, были не в рублях, а тысячах рублей.Как обходить засады
Бывают подводные камни. Например, у нам есть джоб сайт job.ru, если мы воспользуемся формулойjob = grep("job",df$На.каких.работных.сайтах.размещали.резюме,value=F)
job = length(job)/nrow(df)
То мы соберем в эту переменную помимо job еще и весь Superjob, в котором также есть job. Я преодолеваю эту засаду таким образом.
job = q[!grepl("Super",q$На.каких.работных.сайтах.размещали.резюме) & grepl("job",q$На.каких.работных.сайтах.размещали.резюме), ]
job = nrow(job)/nrow(q)
Буквально эта формула означает: мы собираем все, что НЕ содержит Super и содержит job.Ну вот такой маленький кусочек того, что можно делать с результатами вопросов с множественным выбором. Буду рад дополнениям, или если вы покажете, как это сделать проще. Спасибо!
Комментариев нет:
Отправить комментарий