Язык программирования R используется для статистической обработки данных и работы с
графикой. С его помощью можно сделать серьезные расчеты и несерьезные,
например, те, что Вы увидите в данном посте. Для ясности, эту работу делал
новичок в R с целью выработки навыков работы с программой, поэтому, если у Вас
есть дополнения или критика, пожалуйста, напишите в комментариях.
Так как я поклонница вселенной Гарри Поттера,
мне пришла в голову мысль поработать с какими-нибудь данными, связанными с
фильмами о «Мальчике, который выжил».
Хотите узнать насколько кассовые сборы фильмов
о Гарри Поттере больше, чем бюджет, затраченный на их съемки? Также я поставила
перед собой цель проверить гипотезу о том, что, чем больше бюджет фильма, тем
выше кассовые сборы от него.
Загрузим с Википедии таблицу с данными:
library(rvest)
page <- "https://ru.wikipedia.org/wiki/%D0%93%D0%B0%D1%80%D1%80%D0%B8_%D0%9F%D0%BE%D1%82%D1%82%D0%B5%D1%80_(%D1%81%D0%B5%D1%80%D0%B8%D1%8F_%D1%84%D0%B8%D0%BB%D1%8C%D0%BC%D0%BE%D0%B2)"
kino <- html_table(html_nodes(read_html(page),
"table") [[3]], header = TRUE, fill = TRUE, dec=".")
Загруженный датасет, которому я присвоила имя «kino», имеет вид:

Вы наверняка заметили, что таблица загрузилась
не в том виде, в котором она представлена на странице Википедии. Выполним
небольшие преобразования (удалим ненужные столбцы и строки, дадим новые имена
столбцам и др.):
kino <- kino[-c(1,10:12),-7]
kino= `colnames<-`(kino, c('Фильм',"Сборы в США", "Сборы в
других странах", "Всего
сборы","Бюджет","Год"))
row.names(kino)=c(1:nrow(kino))
kino$`Сборы в США` <-
as.numeric(gsub("\\D", "", kino[,2]))/1000000
kino$`Сборы в
других странах` <- as.numeric(gsub("\\D", "", kino[,3]))/1000000
kino$`Всего сборы` <-
as.numeric(gsub("\\D", "", kino[,4]))/1000000
kino$Бюджет <-
as.numeric(gsub("\\D", "", kino[,5]))/1000000

Посмотрим summary(kino):

Из сводки видно, что максимальная сумма,
потраченная на съемки фильма (столбец «Бюджет») равна 250 млн долл., а минимальная
сумма кассовых сборов (столбец «Всего сборы») более 796 млн. долл. Выгода –
более, чем в 3 раза.
Давайте визуализируем данные о бюджете всех
фильмов:
library(ggplot2)
ggplot(data=kino, aes(x=Фильм, y=Бюджет)) +geom_col(size=2, fill="pink3",color
= 'black') + geom_text(aes(label=Бюджет), size=5, vjust = -0.5, hjust = 0.5) + theme_minimal(base_size = 20) + theme(axis.text.x = element_text(angle = 90,
hjust = 1))

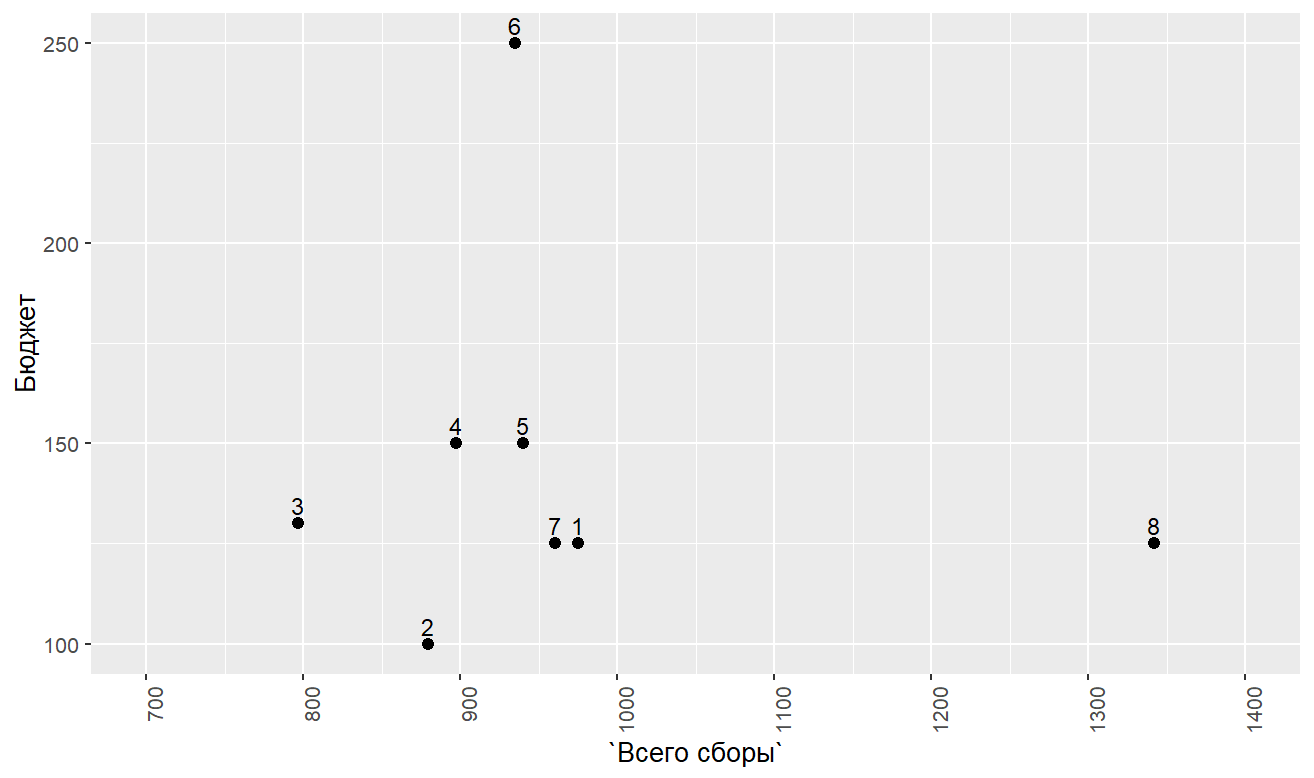
Точечная
диаграмма между «Бюджетом» и «Всего сборами» представлена ниже. Цифры рядом с
точками означают порядковый номер фильма из датасета «kino».
ggplot(data=kino, aes(x=`Всего сборы`, y=Бюджет)) +geom_count(size=4,
fill="pink3",color = 'black') +
geom_text(aes(label=rownames(kino)), size=6, vjust = -0.5, hjust = 0.5)
+ theme_grey(base_size = 20) + theme(axis.text.x = element_text(angle = 90,
hjust = 1))+ scale_x_continuous(breaks =
round(seq(700, 1400, by = 100),0), limits
= c (700, 1400))
Если рассмотреть общую сумму бюджета всех 8
фильмов и общую сумму кассовых сборов, то мы получим такой «пирог»:
a <- t(data.frame(sum(kino$Бюджет),sum(kino$`Всего сборы`)))
pie(a, labels=a[,1],col=c("cyan", "aquamarine"))

Из рисунка видно, что затраченные средства (в
размере 1155 млн долл.) на съемки 8 фильмов намного меньше, чем выручка (7725 млн
долл.) от них.
write.csv2(kino,"kino.csv")
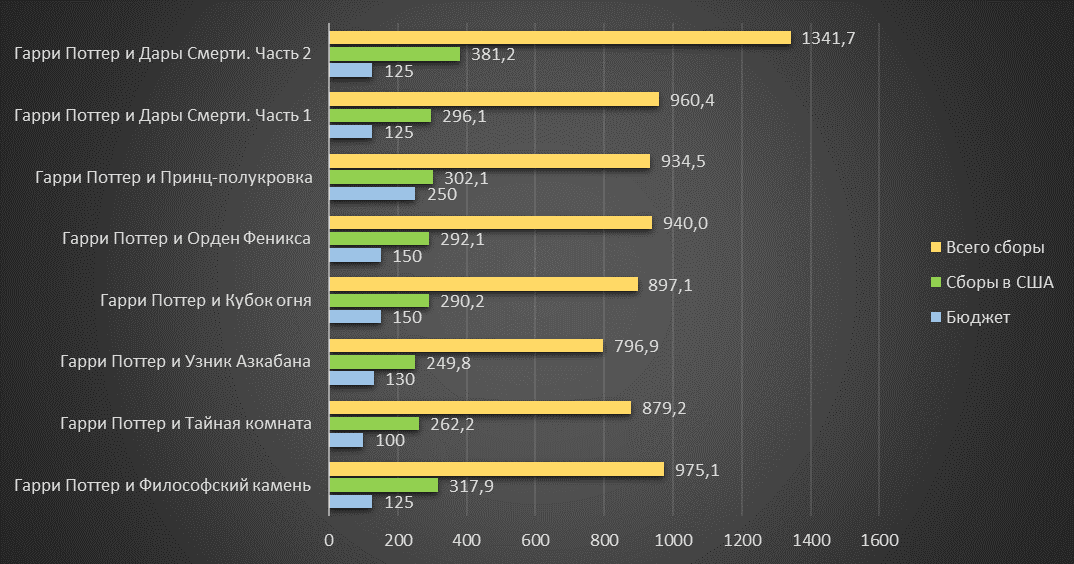
И снова мы наглядно убеждаемся, что кассовые
сборы намного превышают бюджет фильмов.
Чтобы проверить зависимость между бюджетом,
затраченным на съемки и полученной прибылью от кассовых сборов воспользуемся
коэффициентом корреляции Спирмена, так как обе выборки имеют ненормальное
распределение (проверка с помощью критерия Шапиро-Уилка):
cor.test(kino$Бюджет,kino$`Всего сборы`,method="spearman")

Получается, что можно подтвердить нулевую
гипотезу о том, что нет связи между бюджетом фильма и кассовыми сборами от него,
слишком велико p-value (гораздо больше «положенных» 0.05 и даже «либеральных»
0.1).
Комментариев нет:
Отправить комментарий