До сих в блоге в прогнозе текучести персонала я пользовался моделями дожития, изредка классификации. Эти модели хороши, но у них есть один недостаток: они не схватывают эпидемии миграции работников. Эпидемии могут быть вызваны каким-то внешним или внутренним фактором (непопулярное решение начальства, появление крутого конкуренты в регионе и т.п..). И в этом случае дожитие, которое строит глубинные прогнозы про индивидуума, становится бессильно, как человек, который вел здоровый образ жизни, был сметен эпидемией.
Вот как раз для такого рода эпидемий очень даже неплохо подходят модели временных рядом - Time Series.
 Перед вами диаграмма текучести персонала одного ритейлера. Данные реальные - в этм собственно ценность данного поста.
Перед вами диаграмма текучести персонала одного ритейлера. Данные реальные - в этм собственно ценность данного поста.
По оси X - время (вы видите начало периода - начало 2014 года), а заканчивается августом 2017 года - свежак просто;
По оси Y - количество уволившихся работников.
Задача стоит так: можем ли мы на основе предыдущих периодов предсказать, сколько уволится (или будет уволено) в будущем месяце. Согласитесь, очень классная задача, которая тянет на workforce planning.
Первое, что мы делаем - определяем базовую точность прогноза. Точность модели в нашем случае измеряем с помощью RMSE - отклонение нашего прогноза текучести от реального. В человеках.
Базовая точность считается очень просто: мы как бы прогнозируем, что текучесть будущего месяца будет равна текучести текущего месяца. Проще: в сентябре 2017 года уволится столько же, сколько в августе. И эту "точность" модели примем за базовую Если наш прогноз будет точнее данного "прогноза", мы скажем, что модель рабочая, мы можем ее применять.
 Я взял только последние 12 месяцев - от сентября 2016 года до августа 2017 года.
Я взял только последние 12 месяцев - от сентября 2016 года до августа 2017 года.
Обратите внимание, зеленая линия повторяет синюю с опозданием на месяц.
RMSE 32.953. Запомните эту цифру, это наш базовый прогноз. Наша ошибка - 33 человека. И задача эту ошибку сократить, чтобы мы ошибались не на 33 человека, а меньше.
В этом посте я не буду показывать код, вы можете самостоятельно сделать это по шаблонам:
Если вы работает в Python - A comprehensive beginner’s guide to create a Time Series Forecast (with Codes in Python)
Если вы работает в R - A Complete Tutorial on Time Series Modeling in R
Начинать лучше со второго поста про R, поскольку там описана методология временных рядов, важно для понимания результатов. И обратите внимание на фразу автора первого поста: "Many resources exist for TS in R but very few are there for Python". Это к вопросу о том, каким инструментом пользоваться.
В этом посте я использую модель ARIMA. Далее покажу, как работает нейронная сеть.
О технических вещах добавлю только, что тест Dickey-Fuller показал, что наша текучесть персонала в компании не стационарна, мы преобразовываем ее.
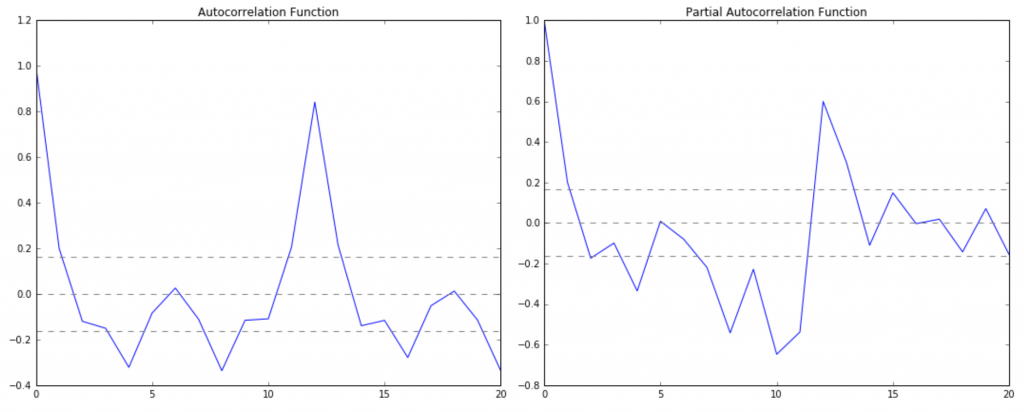
Графики ACF - PACF

Диаграммы выше показывают какой временной лаг значим в прогнозе.
Пунктиром показаны границы значимости. В случае авторегрессии (левый рисунок) лучше всего дает прогноз предыдущий месяц (обратите внимание - прям на границе значимости), в случае скользящего среднего (правый рисунок) - смещение на 10 месяцев (что это интересно за цикл в 10 месяцев???). И нас разочаровал лаг в 12 месяцев. Он на правом рисунке упирается в границу значимости, но не смог выйти за ее пределы. Что это значит для нас? Мы по идее могли бы сказать, что в январе уволится примерно столько, сколько уволилось в прошлом январе, но данная картинка нам не позволяет так уверенно это заявлять. Чтобы вы могли оценить масштаб бедствия, посмотрите на картинку из поста по ссылке
 Это прогноз количества пассажиров. Сравните, насколько лаг в 12 месяцев подскакивает над планкой?
Это прогноз количества пассажиров. Сравните, насколько лаг в 12 месяцев подскакивает над планкой?
Нас канешка же настораживает эта ситуация, но мы смело идем к финишу
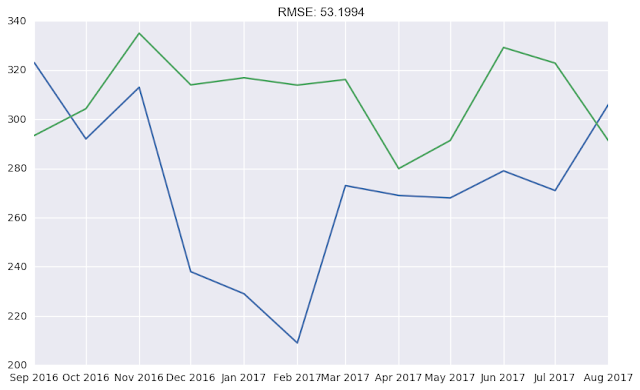 Обратите внимание на RMSE выше. 53. А наш базовый прогноз? ну или сравните картинки.
Обратите внимание на RMSE выше. 53. А наш базовый прогноз? ну или сравните картинки.
Вам вопрос: что может быть не так в данных? Что бы вы посмотрели в данных, чтобы вы исправили?
Хотите сделать для своей компании? обращайтесь Контакты
На этом все, читайте нас в фейсбуке и телеграм
Вот как раз для такого рода эпидемий очень даже неплохо подходят модели временных рядом - Time Series.
Как это работает?

По оси X - время (вы видите начало периода - начало 2014 года), а заканчивается августом 2017 года - свежак просто;
По оси Y - количество уволившихся работников.
Задача стоит так: можем ли мы на основе предыдущих периодов предсказать, сколько уволится (или будет уволено) в будущем месяце. Согласитесь, очень классная задача, которая тянет на workforce planning.
Решение
Чайникам, кто не аналитик, рекомендую сразу в конец поста, чтобы почитать результаты анализа.Первое, что мы делаем - определяем базовую точность прогноза. Точность модели в нашем случае измеряем с помощью RMSE - отклонение нашего прогноза текучести от реального. В человеках.
Базовая точность считается очень просто: мы как бы прогнозируем, что текучесть будущего месяца будет равна текучести текущего месяца. Проще: в сентябре 2017 года уволится столько же, сколько в августе. И эту "точность" модели примем за базовую Если наш прогноз будет точнее данного "прогноза", мы скажем, что модель рабочая, мы можем ее применять.

- Синяя линия - наши реальные данные;
- Зеленая - наш "прогноз".
Обратите внимание, зеленая линия повторяет синюю с опозданием на месяц.
RMSE 32.953. Запомните эту цифру, это наш базовый прогноз. Наша ошибка - 33 человека. И задача эту ошибку сократить, чтобы мы ошибались не на 33 человека, а меньше.
В этом посте я не буду показывать код, вы можете самостоятельно сделать это по шаблонам:
Если вы работает в Python - A comprehensive beginner’s guide to create a Time Series Forecast (with Codes in Python)
Если вы работает в R - A Complete Tutorial on Time Series Modeling in R
Начинать лучше со второго поста про R, поскольку там описана методология временных рядов, важно для понимания результатов. И обратите внимание на фразу автора первого поста: "Many resources exist for TS in R but very few are there for Python". Это к вопросу о том, каким инструментом пользоваться.
В этом посте я использую модель ARIMA. Далее покажу, как работает нейронная сеть.
О технических вещах добавлю только, что тест Dickey-Fuller показал, что наша текучесть персонала в компании не стационарна, мы преобразовываем ее.
Графики ACF - PACF

Диаграммы выше показывают какой временной лаг значим в прогнозе.
Пунктиром показаны границы значимости. В случае авторегрессии (левый рисунок) лучше всего дает прогноз предыдущий месяц (обратите внимание - прям на границе значимости), в случае скользящего среднего (правый рисунок) - смещение на 10 месяцев (что это интересно за цикл в 10 месяцев???). И нас разочаровал лаг в 12 месяцев. Он на правом рисунке упирается в границу значимости, но не смог выйти за ее пределы. Что это значит для нас? Мы по идее могли бы сказать, что в январе уволится примерно столько, сколько уволилось в прошлом январе, но данная картинка нам не позволяет так уверенно это заявлять. Чтобы вы могли оценить масштаб бедствия, посмотрите на картинку из поста по ссылке
Нас канешка же настораживает эта ситуация, но мы смело идем к финишу
Финальный прогноз

Итого
На примере данной компании использование временных рядов модели ARIMA не позволяет нам пока прогнозировать текучесть персонала.Вам вопрос: что может быть не так в данных? Что бы вы посмотрели в данных, чтобы вы исправили?
Хотите сделать для своей компании? обращайтесь Контакты
Понравился пост?
и Вы захотите выразить мне благодарность, просто покликайте на директ рекламу ниже на странице - у вас это отнимет несколько секунд, а мне принесет немного денег.На этом все, читайте нас в фейсбуке и телеграм
Комментариев нет:
Отправить комментарий