Специальная вводная на англоязычных читателей
This post is an attempt to forecast the monthly turnover of personnel using the LSTM neural networks. As predictors, I used 1) shifted monthly staff turnover, 2) the level of employee engagement, 3) information on the awards.
The diagram chart shows the staff turnover level on a monthly basis in%. The second diagram is the base forecast obtained by the formula "% next month" = "% current month. " The basic error RMSE for this" forecast "is 0.891.
The third diagram is our prediction based on the LSTM neural network. Using the LSTM neural network with these predictors allows us to reduce the error to 0, 71. This forecast is far from ideal, but it allows us to hope that with the accumulation of data we will be able to improve it.
Любителям получать однозначные ответы сразу скажу, что я не ответил на вопрос, влияет ли вовлеченность персонала на текучесть. Пост будет интересен тем, кто любит копаться в задачках.
Задачка - расширение задачки Прогноз текучести персонала на основе временных рядов. Модель ARIMA. У нас по прежнему есть 1) текучесть персонала в компании по месяцам в % 2) лаг этой текучести.
Поясняю: задача временных рядов сводится к ответу на вопрос, можем ли мы предсказать нынешнее состояние на основе предыдущих состояний. Т.е. можем ли мы спрогнозировать % текучести персонала в следующем месяце на основе того, сколько у нас уходило в этом месяце, в прошлом и т.п. (сюда же относится сезонность, когда мы говорим, что в январе текучесть будет меньше (или больше), потому что сезон).
Но три датасета, которые мне любезно предоставили коллеги HR, показали, что прогноз только на основе предыдущих периодов дает очень слабый прогноз. Это может объясняться в том числе малым объемом данных, но и тем не менее.
Отсюда встает задача данных: где бы нам набрать данных, которые бы позволили улучшить наш прогноз. Я смог вытащить у коллег такую информацию:


This post is an attempt to forecast the monthly turnover of personnel using the LSTM neural networks. As predictors, I used 1) shifted monthly staff turnover, 2) the level of employee engagement, 3) information on the awards.
The diagram chart shows the staff turnover level on a monthly basis in%. The second diagram is the base forecast obtained by the formula "% next month" = "% current month. " The basic error RMSE for this" forecast "is 0.891.
The third diagram is our prediction based on the LSTM neural network. Using the LSTM neural network with these predictors allows us to reduce the error to 0, 71. This forecast is far from ideal, but it allows us to hope that with the accumulation of data we will be able to improve it.
Итак,
Все прогрессивное человечество HR ждет ответа на вековечный вопрос, влияет ли вовлеченность персонала на текучесть или нет. Ну кроме откровенных м.даков, которые это знают а приори.Любителям получать однозначные ответы сразу скажу, что я не ответил на вопрос, влияет ли вовлеченность персонала на текучесть. Пост будет интересен тем, кто любит копаться в задачках.
Задачка - расширение задачки Прогноз текучести персонала на основе временных рядов. Модель ARIMA. У нас по прежнему есть 1) текучесть персонала в компании по месяцам в % 2) лаг этой текучести.
Поясняю: задача временных рядов сводится к ответу на вопрос, можем ли мы предсказать нынешнее состояние на основе предыдущих состояний. Т.е. можем ли мы спрогнозировать % текучести персонала в следующем месяце на основе того, сколько у нас уходило в этом месяце, в прошлом и т.п. (сюда же относится сезонность, когда мы говорим, что в январе текучесть будет меньше (или больше), потому что сезон).
Но три датасета, которые мне любезно предоставили коллеги HR, показали, что прогноз только на основе предыдущих периодов дает очень слабый прогноз. Это может объясняться в том числе малым объемом данных, но и тем не менее.
Отсюда встает задача данных: где бы нам набрать данных, которые бы позволили улучшить наш прогноз. Я смог вытащить у коллег такую информацию:
- показатели вовлеченности персонала;
- информацию о квартальной премии.
- 2014 49%
- 2015 62%
- 2016 71%
- 2017 63%

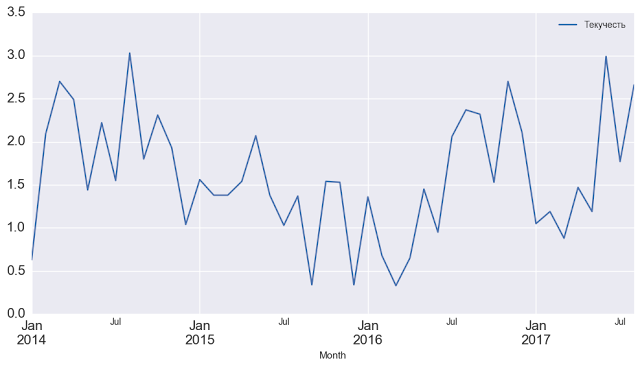
- По оси X - месяцы
- По оси Y - текучесть персонала в %
Заодно сразу прикиньте, как тут вовлеченность связана с текучестью. Но проблема измерения очевидна: текучесть мы измеряем помесячно, вовлеченность раз в год опросом, хотя очевидно, что текучесть не стоит на месте весь год. Отсюда сразу вопросы к точности. Я здесь боюсь обращаться к тем, кто проводит пульс опросы вовлеченности по одной простой причине: да, в ваших компаниях можно было бы измерить связь между вовлеченностью и текучестью точнее, но, боюсь, что в России нет ни одной компании, которая бы на сегодняшний день измеряла вовлеченность персонала с помощью пульс опросов.
Решение
Сначала измеряем базовую точность модели. Базовая точность измеряется как возможность прогноза текучести будущего месяца на основе предыдущего. Т.е. тупо, мы говорим, что в будущем месяце будет уходить такой же % персонала, как в этом

- По оси X - последние 12 месяцев (от сентября 2016 до августа 2017);
- Ось Y - текучесть в % также;
- Синяя линия - наша реальная текучесть;
- Зеленая - прогнозная.
Заметно, что зеленая линия повторяет синию с лагом в один месяц. Базовая точность в нашем случае измеряется с помощью ошибки RMSE (или MAE) - это разница между нашей реальной текучестью и прогнозной.
В вышеприведенном случае наша ошибка равна 0.891.
Много это или мало? Среднее значение текучести по месяцу равно 1, 82 %, а ошибка 0, 891 (практически 0, 9 %). Т.е наше прогнозное значение будет плюс минус 0, 9 по отношению к реальному. И если мы по месяцу имеем текучесть 1,5 %, то наш прогноз будет в пределах 0, 6 - 2,3 %. Не очень здорово. Но это базовая точность модели.
Много это или мало? Среднее значение текучести по месяцу равно 1, 82 %, а ошибка 0, 891 (практически 0, 9 %). Т.е наше прогнозное значение будет плюс минус 0, 9 по отношению к реальному. И если мы по месяцу имеем текучесть 1,5 %, то наш прогноз будет в пределах 0, 6 - 2,3 %. Не очень здорово. Но это базовая точность модели.
И наша задача создать модель прогноза, которая бы имела ошибку меньше базовой, менее 0, 891. Любой значение менее 0, 891 скажет нам, что наша модель имеет право на существование.
Не буду вас утомлять анализом, результат такой

Эта диаграмма аналогична диаграмме выше с той разницей, что мы сделали прогноз на основе трех переменных:
- текучесть персонала прошлого месяца;
- показатель вовлеченности персонала по году;
- информация о квартальной премии.
Ошибка прогноза 0.71. И это лучше, чем наша базовая точность, но далека от идеала. Рецепта улучшения точности модели два:
- собирать данные;
- накапливать больше периодов.
По поводу собирать данные - это очень хороший вопрос. Я не встречал ни одного подобного кейса, точнее слышал, что такое делали, но не знаю, какие данные использовали. Но понятно, что текучесть может определяться как внешними событиями на рынке (политика конкурентов, глобальные тренды типа политики России и т.п.), так и внутренними - политики мотивации (размер премии), соц пакет и т.п..
Если у вас есть желание поработать с такой задачей у себя в компании - обращайтесь, контакты по ссылке.
__________________________________________________________
На этом все, читайте нас в фейсбуке и телеграмме
Комментариев нет:
Отправить комментарий