Методология, стоящая за этим постом, чрезвычайно проста: закрытые вопросы заполняются респондентом в корпоративном исследовании часто на автомате, лишь бы отвязались. Т.е. дело даже не в социальной желательности, а просто в автомате. И открытый вопрос опросника вовлеченности часто является фильтром для социально желательных: респондент социально желательно отвечает на закрытые вопросы, но на открытые либо вообще не отвечает, либо отвечает по типу: да все отлично. Таким образом, Открытые вопросы опросников вовлеченности сами по себе являются более "чистым" вариантом опросника вовлеченности и удовлетворенности.
Кроме того, анализ тем или тематическое моделирование (см по ссылке пост Людмилы Роговой) позволяет выделить смысловые блоки ответов. И это также является фильтром социально желаемых ответов: опасность, правда, в том (и я с этим уже сталкивался), что бОльшая часть респондентов отвечают, как все замечательно, и в этом случае мы делаем вывод, анализировать такие открытые вопросы опросников вовлеченности смысла нет.
Приведу пример анализа открытых вопросов опросника вовлеченности
В опроснике одной из компании Людмила Рогова провела тематическое моделирование открытых вопросов и получила по каждому открытому вопросу несколько тем.
Я (помимо всего прочего) сделал такой анализ: напротив каждого респондента появилось несколько колонок, каждая колонка - тема открытого опроса. Если респондент упоминал тему в своем ответе, стоит "1", нет - "0".
Далее, я применяю критерий Манн Уитни для двух групп (тема открытого вопроса по уровню удовлетворенности)
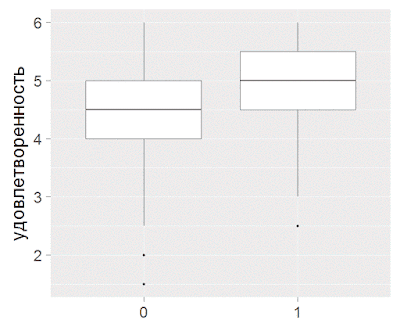
Те, кто упоминали одну из тем на вопрос «Что бы вы сделали, чтобы как можно больше людей узнали о нас и пришли к нам» показывали более значимые результаты по удовлетворенности в данном вопросе.
 Но более удивительным оказалось другое: те, кто упоминали одну из тем в открытом вопросе вовлеченности «Что бы Вы улучшили в работе компании?» показывали значимо более низкие результаты по вовлеченности. Открою секрет, что эта тема открытого вопроса вовлеченности была связана сильно со словом "зарплата".
Но более удивительным оказалось другое: те, кто упоминали одну из тем в открытом вопросе вовлеченности «Что бы Вы улучшили в работе компании?» показывали значимо более низкие результаты по вовлеченности. Открою секрет, что эта тема открытого вопроса вовлеченности была связана сильно со словом "зарплата".
 Далее мы смотрим % упоминавших темы открытого вопроса вовлеченности в разрезах категорий персонала, филиалов и т.п... И получаем рейтинги вовлеченности. На картинке показан разрез по филиалам (названия я, конечно, не могу сказать): т.е. в самом лучшем филиале 21 % респондентов поминал данную тему, в самом худшем - только 5 %.
Далее мы смотрим % упоминавших темы открытого вопроса вовлеченности в разрезах категорий персонала, филиалов и т.п... И получаем рейтинги вовлеченности. На картинке показан разрез по филиалам (названия я, конечно, не могу сказать): т.е. в самом лучшем филиале 21 % респондентов поминал данную тему, в самом худшем - только 5 %.
А если мы наложим две темы друг на друга, то получим
 По осям у нас - темы открытых вопросов, точки это филиалы (ну не могу я названия дать), значение по оси X и Y определяется % упоминувших эти темы в открытом вопросе вовлеченности.
По осям у нас - темы открытых вопросов, точки это филиалы (ну не могу я названия дать), значение по оси X и Y определяется % упоминувших эти темы в открытом вопросе вовлеченности.
Розовый и зеленый квадранты как бы логичные квадранты: там % "хороших" и "плохих" ответов связаны между собой: чем больше "хороших" ответов, тем меньше "плохих", а вот точки из серых квадрантов не очень логичны: в филиале 10 максимальный % респондентов показал "плохие" ответы, связанные с неудовлетворенностью зарплатой, но готовность продвигать компанию при этом выше среднего по компании.
Интерпретировать не буду, думаю, что вы как потребители результатов должны сами предлагать рекомендации в данном случае. Мне только очень важно: напишите, пожалуйста, насколько в принципе понятна логика поста. Ругаться не буду, просто напишите: понятно изложение или нет.
Хотите получать подобные результаты в своем корпоративном исследовании? пишите edvb()yandex.ru
И не забывайте о семинаре по HR-аналитике в R 20-21 июня!
Кроме того, анализ тем или тематическое моделирование (см по ссылке пост Людмилы Роговой) позволяет выделить смысловые блоки ответов. И это также является фильтром социально желаемых ответов: опасность, правда, в том (и я с этим уже сталкивался), что бОльшая часть респондентов отвечают, как все замечательно, и в этом случае мы делаем вывод, анализировать такие открытые вопросы опросников вовлеченности смысла нет.
Приведу пример анализа открытых вопросов опросника вовлеченности
В опроснике одной из компании Людмила Рогова провела тематическое моделирование открытых вопросов и получила по каждому открытому вопросу несколько тем.
Я (помимо всего прочего) сделал такой анализ: напротив каждого респондента появилось несколько колонок, каждая колонка - тема открытого опроса. Если респондент упоминал тему в своем ответе, стоит "1", нет - "0".
Далее, я применяю критерий Манн Уитни для двух групп (тема открытого вопроса по уровню удовлетворенности)
Рисунок 1

Те, кто упоминали одну из тем на вопрос «Что бы вы сделали, чтобы как можно больше людей узнали о нас и пришли к нам» показывали более значимые результаты по удовлетворенности в данном вопросе.
Рисунок 2

Рисунок 3

А если мы наложим две темы друг на друга, то получим
Рисунок 4

Розовый и зеленый квадранты как бы логичные квадранты: там % "хороших" и "плохих" ответов связаны между собой: чем больше "хороших" ответов, тем меньше "плохих", а вот точки из серых квадрантов не очень логичны: в филиале 10 максимальный % респондентов показал "плохие" ответы, связанные с неудовлетворенностью зарплатой, но готовность продвигать компанию при этом выше среднего по компании.
Интерпретировать не буду, думаю, что вы как потребители результатов должны сами предлагать рекомендации в данном случае. Мне только очень важно: напишите, пожалуйста, насколько в принципе понятна логика поста. Ругаться не буду, просто напишите: понятно изложение или нет.
Хотите получать подобные результаты в своем корпоративном исследовании? пишите edvb()yandex.ru
Понравился пост?
и Вы захотите выразить мне благодарность за интересные результаты, просто покликайте на директ рекламу ниже на странице - у вас это отнимет несколько секунд, а мне принесет немного денег.И не забывайте о семинаре по HR-аналитике в R 20-21 июня!
Последний 4-й рисунок и описание кажутся не совсем попятными. По крайней мере для меня.
ОтветитьУдалитьАлександр, спасибо! попробую объяснить
УдалитьСмотрите на рисунок 3.
мы получили рейтинг филиалов, так?
далее я просто нормализую этот рейтинг: беру среднее значение от % давших отзыв и делю на стандартное отклонение. Таким образом мы получаем нормализованные значения. В итоге у нас на правом фланге стоят филиалы, у кого лучше всего с отзывами по по вопросу «Что бы Вы улучшили в работе компании?» - те, у кого всего по 5 % респондентов, кто дали такие отзывы.В итоге у нас переход от зеленой к красной зоне - это среднее значение % респондентов. В нормальном распределении это значение равно 0.
По оси Y мы делаем тоже самое, но уже по другому вопросу - «Что бы вы сделали, чтобы как можно больше людей узнали о нас и пришли к нам» - считаем % респондентов, кто написали такую то тему, нормализуем. Откладываем по шкале Y.
Понятней? честно?
Эдуард, да, спасибо, вроде доехал.
УдалитьДолгое время думала, что открытые вопросы позволяют извлечь только мнения и отношения к исслуемому предмету. Потом в нескольких статьях встретила, что результаты можно использовать для дальнейшего анализа как новые переменные, но даже не знала с какой стороны подойти к этому. Сейчас увидела четкий конкретный пример как дальше это можно делать) Спасибо!
ОтветитьУдалитьЛюда, а описание понятно? честно?
УдалитьМне да. Хотя комментарий к 4-му рисунку прочитала пару раз. А для нормализации ведь вроде надо из значения вычесть среднее, и полученную разность на std поделить, а то я из описания немного не то поняла
Удалитьда, нормализация простая: 0, 21 + 0, 19 +...+ 0, 05 / количество филиалов, получаем среднее.
Удалитьпотом делим на стандартное отклонение
Я честно говоря, нормализовал, потому что посчитал, что у клиентов больше вопросов возникнет, если не нормализовать: а что это за цифры и т.п...
Плюс вопрос масштаба - нам же обе оси надо привести к соразмерных расстояниям
Но в простом варианте описания для клиента это звучит так:
ОтветитьУдалитьпо оси X это рейтинг по вопросу Что бы Вы улучшили в работе компании? - чем правее, тем лучше ситуация в филиале, а Y это рейтинг филиала по вопросу Что бы вы сделали, чтобы как можно больше людей узнали о нас и пришли к нам
При этом Что бы Вы улучшили в работе компании? - это "плохой" вопрос, а Что бы вы сделали, чтобы как можно больше людей узнали о нас и пришли к нам - "хороший".
потому что те, кто пишут по первому вопросу значимо меньше удовлетворены, а те, кто пишут по второму - значимо выше удовлетворены.
следовательно, логично было бы ожидать, что в тех филиалах, где больше плохих ответов, меньше хороших.
Но такая логика не везде прослеживается