В газете Ведомости вышла недавно статья Как вычислить сотрудников, собирающихся уволиться. В статье описывался опыт управления текучестью на основе машинного обучения, среди прочего там была такая фразу:
В вышеуказанном тексте два утверждения, разбираю последовательно
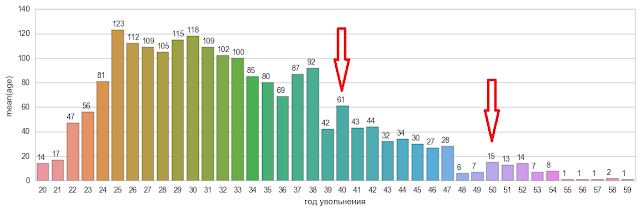 Я специально выделил вехи в 40 и 50 лет. Заметно, что, по крайней мере, 40 летняя веха выдается над соседними годами. С другой стороны, у нас рядом есть 37 и 38 летние вехи, которые тоже вроде как выдаются над соседними годами. И главная проблема данного анализа - мы не можем применить простой и понятный инструмента - карты Шухарта (а по русски - отклонение выбросов от среднего) по той причине, что у нас возрасты распределены не равномерно, не как масло на бутерброде, а очень неравномерно.
Я специально выделил вехи в 40 и 50 лет. Заметно, что, по крайней мере, 40 летняя веха выдается над соседними годами. С другой стороны, у нас рядом есть 37 и 38 летние вехи, которые тоже вроде как выдаются над соседними годами. И главная проблема данного анализа - мы не можем применить простой и понятный инструмента - карты Шухарта (а по русски - отклонение выбросов от среднего) по той причине, что у нас возрасты распределены не равномерно, не как масло на бутерброде, а очень неравномерно.
Резюме: мы должны понять, как считать ожидаемое количество увольнений.
У меня родилась такая идея (воруйте идею): я вычисляю медиану стажа этих респондентов, далее я к возрасту трудоустройства прибавляю эту медиану стажа и получаю ожидаемое распределение увольнение по возрасту. Если вы не согласны или готовы предложить своб методику расчета ожидаемого распределения - буду рад услышать.
У меня получилась вот такая картина.
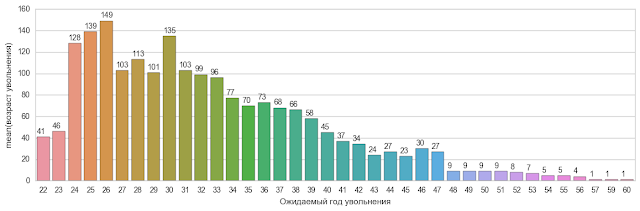 Становится очевидным, что 40 летний рубеж на самом деле отличается от тренда, и мы не отклоняем утверждение компании СЕВ, но с другой стороны 37 и 38 летние увольнянты тоже выбросы. Поэтому утверждение про 40 летних на фоне 37 и 38 летних немного блекнет.
Становится очевидным, что 40 летний рубеж на самом деле отличается от тренда, и мы не отклоняем утверждение компании СЕВ, но с другой стороны 37 и 38 летние увольнянты тоже выбросы. Поэтому утверждение про 40 летних на фоне 37 и 38 летних немного блекнет.
Во-первых, пришлось почистить от мусора, во вторых, я убрал всех со стажем меньше полугода (ну это тоже мусор, поскольку им не дожить до своей годовщины). А дальше следите за руками шулера: я взял дату увольнения как порядковый номер даты года (т.е. 1 января будет номер 1, 31 декабря будет номер 356) и отнял из нее порядковый номер даты трудоустройства.
Для любителей Python дарю код

Т.е. если вы трудоустроились в июне, то уволится вы можете с равной вероятностью в мае, том же июне и феврале. Но я получил вот такую картинку

По оси X - число дней разницы (в абсолютном значении - по модулю) между днем трудоустройства и днем увольнения.
Никак не похоже на однородное распределение.
Как это объяснить?
Единственный подвох я вижу в плохой памяти респондентов, которые на глазок заполняют даты трудоустройства и увольнения, и неосознанно сближают эти даты...
ПОЭТОМУ! Жду от вас (edvb@yandex.ru) ваши данные по трудоустройству и увольнению. Формат файл excel, который содержит две колонки: дата трудоустройства и дата увольнения. И ессессно речь идет только о добровольной текучести: работники сами принимают решение об увольнении.
Но как минимум мы не опровергли утверждение чуваков из CEB, а как максимум мы вышли на важный предиктор текучести персонала.
Ну а я разве не заслужил награды?
__________________________________________________________
На этом все, читайте нас в фейсбуке, телеграмме и вконтакте
И участвуйте в исследовании!
В канун годовщин работы в компании или перехода на текущую должность активность поиска работы повышается на 6 и 9% соответственно. Но вскрылись и факторы, не относящиеся напрямую к работе. Это, например, дни рождения – особенно такие важные вехи, как 40 и 50 лет.Меня эта фраза зацепила. Захотелось проверить корректность этих утверждений для России. Мое преимущество в том, что у меня есть данные для проверки таких гипотез. У вас они же есть: пишите мне, я поделюсь с вами данными, сможете проверить сами любые гипотезы. Но в любом случае приглашаю пройти наше исследование Ключевые факторы текучести персонала.
В вышеуказанном тексте два утверждения, разбираю последовательно
Дни рождения – особенно такие важные вехи, как 40 и 50 лет
Ниже представлена гистограмма увольнения респондентов по возрасту. Здесь представлены увольнения только по инициативе работника.
Резюме: мы должны понять, как считать ожидаемое количество увольнений.
У меня родилась такая идея (воруйте идею): я вычисляю медиану стажа этих респондентов, далее я к возрасту трудоустройства прибавляю эту медиану стажа и получаю ожидаемое распределение увольнение по возрасту. Если вы не согласны или готовы предложить своб методику расчета ожидаемого распределения - буду рад услышать.
У меня получилась вот такая картина.

В канун годовщин работы в компании или перехода на текущую должность активность поиска работы повышается на 6 и 9% соответственно
Сразу предупреждаю, тут я получил какую интересную хреновину.Во-первых, пришлось почистить от мусора, во вторых, я убрал всех со стажем меньше полугода (ну это тоже мусор, поскольку им не дожить до своей годовщины). А дальше следите за руками шулера: я взял дату увольнения как порядковый номер даты года (т.е. 1 января будет номер 1, 31 декабря будет номер 356) и отнял из нее порядковый номер даты трудоустройства.
Для любителей Python дарю код
df['diff'] = pd.to_datetime(df['Дата увольнения ']).apply(lambda x: x.dayofyear) - pd.to_datetime(df['Дата трудоустройства']).apply(lambda x: x.dayofyear)Гипотеза проста: дата увольнения и дата приема никак не связана, и распределение будет как масло на бутерброде - равномерным или однородным. Типа как на картинке

Т.е. если вы трудоустроились в июне, то уволится вы можете с равной вероятностью в мае, том же июне и феврале. Но я получил вот такую картинку

Никак не похоже на однородное распределение.
Как это объяснить?
Единственный подвох я вижу в плохой памяти респондентов, которые на глазок заполняют даты трудоустройства и увольнения, и неосознанно сближают эти даты...
ПОЭТОМУ! Жду от вас (edvb@yandex.ru) ваши данные по трудоустройству и увольнению. Формат файл excel, который содержит две колонки: дата трудоустройства и дата увольнения. И ессессно речь идет только о добровольной текучести: работники сами принимают решение об увольнении.
Но как минимум мы не опровергли утверждение чуваков из CEB, а как максимум мы вышли на важный предиктор текучести персонала.
Ну а я разве не заслужил награды?
__________________________________________________________
На этом все, читайте нас в фейсбуке, телеграмме и вконтакте
И участвуйте в исследовании!
"(т.е. 1 января будет номер 1, 31 декабря будет номер 356)" - 365?
ОтветитьУдалитьда, как то так
УдалитьМеидана стажа этого респондента в этой компании? Или за все периоды работы этого респондента?
ОтветитьУдалить