Идея поста принадлежит Эдуарду Бабушкину. Для меня пост носит обучающий
характер в работе с непонятым до конца mlr, именно поэтому намеренно
работал при решении с ним. От коллег ожидаю обратной связи и ответы на вопросы
в конце поста.
В данном посте решается вопрос
прогнозирования пола на основе данных тестирования. Датасет взят из
многолетнего исследования Ключевые факторы эффективности и текучести персонала Эдуарда Бабушкина.
Гипотеза: интеллект и профиль
черт связан с полом респондента.
Очищенный набор данных содержит
1206 наблюдений с результатами тестов КТО и Big5.
Для дальнейшей работы переменные
перекодированы, в скобках курсивом даны оригинальные наименования:
'data.frame': 1206 obs. of
11 variables:
$ gender (Ваш пол) : Factor w/ 2 levels "Ж","М"
$ iq (Ш1. Общий балл) : num
$ verb (Ш2. Вербальный IQ) : num
$ erud (Ш3. Эрудиция) : num
$ num
(Ш4. Числовой IQ) : num
$ info (Ш5.Обработка информации)
: num
$ extr (Ш6. Экстраверсия-интроверсия) : num
$ auto (Ш7. Независимость-согласие) : num
$ impuls (Ш8. Импульсивность-самоконтроль) : num
$ stab
(Ш9. Тревожность-стабильность) :
num
$ conserv (Ш10. Консерватизм-новаторство): num
Данные подвержены препроцессингу (преобразование
Бокса-Кокса, z-нормирование),
распределение по полу не сбалансированно, количество женщин в наборе данных больше
в 2.8 раз:
Ж М
888 318
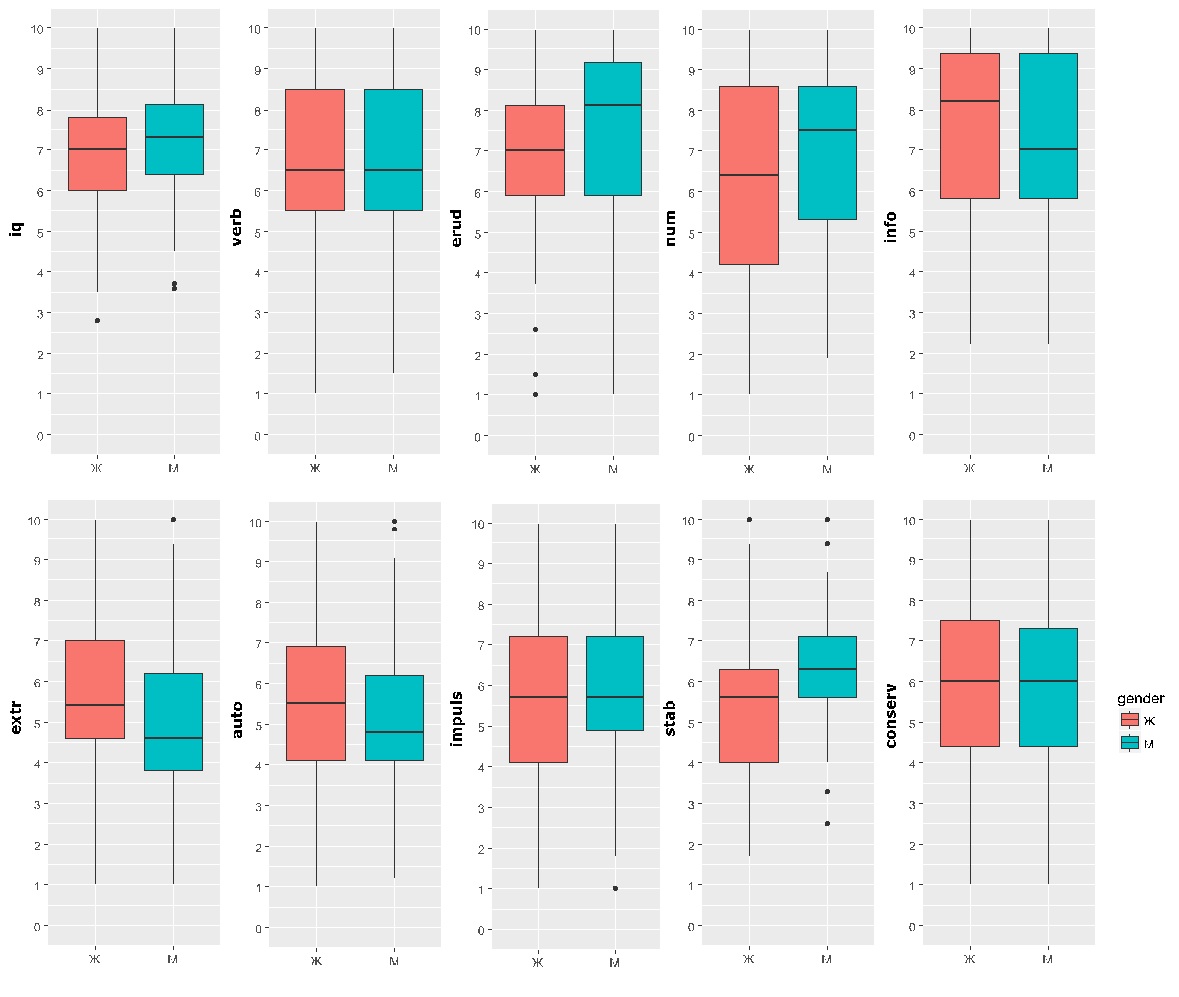
Представляется возможным
предварительно оценить наличие связей с помощью диаграммы боксплот. Наибольшая
разница в медианных значениях в зависимости от пола наблюдается по шкале «Тревожность-стабильность»,
на меньшем уровне по шкалам «Экстраверсия-интроверсия» и «Общий балл IQ».
Кросс-валидация со следующими параметрами: folds = 5L, reps = 10L, maxit = 50L.
Площадь под кривой для построенной модели в зависимости от натренированных параметров:
Параметры модели
auc
0.7799367
Верхние параметры
auc
0.7604274
Нижние параметры
auc
0.7732489
ROC-кривая

График Precision-Recall

В соответствии с полученными графиками вероятность
наступления события установлена на уровне 0.3, тогда
FALSE TRUE
Ж 220
46
М 36
59
Точность модели: 56%.
Наиболее важным фактором оказывается фактор «Тревожность-стабильность»,
на втором месте IQ.

Данные проверяются на новом респонденте:
newdudesclass=data.frame(stab=9.5, iq=9, impuls=4.1,
extr=3.2, auto=4.7, erud=2, num=3, conserv=4, verb=2, info=3)
Prediction: 1 observations
predict.type: prob
threshold: Ж=0.50,М=0.50
time: 0.01
prob.Ж prob.М response
1 0.5934066 0.4065934 Ж
Вывод: в половине случаев, построенная модель позволяет спрогнозировать пол респондента по результатам тестов КТО и Big5.
Вопросы:
1. Как узнать коэффициенты статистической значимости для предикторов в mlr?
2. Нужно ли строить модель только для того варианта параметров (over, under), в котором наблюдается наибольший баланс?
3. Прогноз на новом кандидате даёт response= «Ж» при prob=0.4, но при расчётах вероятность наступления события была установлена на 0.3, можем ли мы считать в таком случае истинным для нас response= «М»?
давайте с базы начнем)
ОтветитьУдалитькакой алгоритм использовали?
Базовые (Ваши) настройки гиперпараметров mlr. Случайны лес "classif.randomForest".
УдалитьКак узнать коэффициенты статистической значимости для предикторов в mlr?
Удалитьа в чем тогда вопрос? Есть вывод модели, есть фиче импортанс - по графику даже видно, что все значимы
причем значимость в модели Рандом форест не обязательно должна сопровождаться значимыми различиями например по Т тесту или Манн Уитни)
или я неправильно понял вопрос
и как вы мульти плот сделали? через какую функцию?
УдалитьЯ просто не был уверен, достаточно ли importance, вероятно, сила привычки. Спасибо!
УдалитьДолго ломал голову как это сделать, в итоге это 10 диаграмм, соединенных в Inkspace.
Ситуация с response для меня все ещё не понятна, причём это не только в случае с mlr , а при любой логит. регрессии - мы на новых данных принимаем решение на том же уровне вероятности, что и для тестовых данных выбрали?
я же вам давал на семинаре про мульти плот. Ну ок
УдалитьИ в mlr есть про порог принятия решения - на новом датасете, я вам это тоже давал, ишите
Вообще на новом датасете вы можете брать любой порог - вы же как бы людей принимаете, тут уж сами решайте
но выбирая порог, просто понимаете риски
Я с мультиплота с семинара начал, но для варианта 10 диаграмм оказалось менее смотрибельно. Да, техническую установку threshold я в скрипте увидел, просто это больше вопрос ориентиров был (либо точность, либо объём :)
Удалитьна самом деле можно попробовать функцию pairs - я вам ее тоже давал
Удалитьполучается матрица интеркорреляций, о чем коллега попросил
https://edwvb.blogspot.ru/2017/05/interkorrelyacii-kratkogo-otborochnogo-testa-i-bolshoj-pyaterki-big5.html
но вы посмотрите pairs под ggplot - и у вас должна матрица боксплотов появиться
получается вот так
https://edwvb.blogspot.ru/2016/12/v-kakoe-vremya-sutok-luchshe-prohodit-psihologicheskie-testy.html
этот пост как вы заметили в Питоне сделан, но в R можно тож самое - в любом случае подобные посты требуют таких визуализаций для понимания различий
По поводу "мы на новых данных принимаем решение на том же уровне вероятности, что и для тестовых данных выбрали" - да, необходимо принимать на том же уровне вероятности, так как "тестовые данные" по сути являются новыми для модели и порог отсечения мы выбирали как раз оптимальный для новых данных.
УдалитьОлег, позвольте с вами не согласиться. На новых данных мы принимаем решение так, как нам выгодней, при чем здесь тестовая выборка?
УдалитьПредставьте, Вам Евгений Бондаренко двух кандидатов в кадровый резерв прислал? Чтобы кого то одного включить.
Вы на какой уровень будете ориентироваться? Вы будете ориентироваться на то, у кого вероятность попадания в кадровый резерв выше.
Вот и все.
С вами не соглашусь, у вас задача классификации все-таки, а не регрессии, вы на выходе получаете не число - вероятность, а класс. И настраиваете свой уровень отсечения опять же ориентируясь, что вы прогоняете всех людей через классификатор. И утверждать, что при вероятности по одному сотрудника в 90%, а по другому в 80%, нужно выбирать того, у которого выше - в корне неверно, нужно ориентироваться на присвоенный класс.
УдалитьПоясните еще раз: у вас два кандидата, у одного 0, 9 вероятность, у другого 0, 8. Вам нужно выбрать одного
Удалитьвы будете ориентироваться на присвоенный класс.
И как вы будете принимать решение в данной ситуации?
* то, что я в корне не прав, это я понял. Но я бы хотел услышать от вас конструктив
Если они принадлежат к одному классу, то принимать решение нужно по другому индикатору значит.
УдалитьТо что у одного вероятность 0.9, а у другого 0.8, в данном случае, лишь означает что 90% деревьев в случайном лесе проголосовало, что первый кандидат принадлежит к классу 1, и 80% деревьев проголосовало, что второй кандидат принадлежит к классу 1. Если вы перестроите модель и поставите количество деревьев, больше или меньше - эти числа могут запросто измениться на другие. И при этом, в отличии от классической классификации, вы не можете даже теоретически подсчитать вероятность вашей ошибки, т.е. что на самом деле вероятность второго сотрудника выше чем у первого. Нельзя даже утверждать, что в среднем кандидат с большей вероятностью более привлекателен чем второй, у которого вероятность меньше.
Если вы считаете иначе, прошу также конструктивно это доказать.
Начнем с того, что я уже второй раз ловлю на том, что вы просто не читаете чужие тексты. Это не очень здорово.
УдалитьПо теме.
В любом другом алгоритме показатель вероятности точно также будет зависеть от трейн тест сплит и выбранных параметров модели. Если вы перестроите модель в любом алгоритме (просто зададите новый set.seed), то у кандидатов обязательно поменяются вероятности. И вполне допускаю, что у того, кого было 0, 9 станет меньше, чем 0, 8
Отсюда вопрос: так на основе чего мы все таки будем принимать решение? у нас есть порог классификации и вероятность.
У вас, правда, в запасе какой то индикатор оказался, у меня его нет
Окей, сокращу ту логику, которую я тщетно пытался донести - если классификатор присваивает обоим сотрудникам одинаковый класс (класс присваивается, конечно, исходя из найденного порога классификации на тестовых данных) - то они для нас равнозначны, точка. Есть у вас другой какой-то индикатор, помимо результата классификатора - отлично, если нет, тогда обоснованное решение в пользу любого из кандидатов не принять. И интересно, если я повторно пишу, почти один и тот же текст, кто из нас не читаете чужие тексты?
УдалитьВы меня просили привести конструктивно доказать вам? Не знаю, насколько конструктивно, но я вам привел свою логику.
УдалитьЕсли вы хотели бы обсуждать со мной конструктивно, вы бы нашли в моей логике изьян. И показали бы мне его.
Вы в место этого ограничились констатацией своей позиции. Ну ок, но мне все таки хотелось бы услышать аргументы.
Хотелось бы посмотреть на корреляционную матрицу. Также, учитывая специфику предикторов и датасета в целом, скорее всего randomforest не будет здесь хорошо себя показывать. Рекомендую попробовать алгоритмы glm, gam и xgb, и сравнить результаты.
ОтветитьУдалитьИ не забывать за балансировку данных.
готов поспорить, что случайный лес даст лучшие результаты, чем просто лог регрессия:)
Удалитьхотя я, как мне кажется, понимаю вашу логику: результаты тестов нормально распределены, для них по идее должны хорошо работать параметрические модели. Но тут есть еще одна фишка - не гарантирую, что сработает, но думаю, что да
Спорить не вижу смысла, это ж просто "пальцем в небо") но предпосылки о том, что лог регрессия покажет хороший результат есть. Надеюсь автор сможет проверить и сообщить AUC по каждой из модели, очень интересно. Благо mlr пакет позволяет это довольно быстро сделать
Удалитьтут не о чем спорить, надо просто матчасть знать
УдалитьОлег, но если вы знаете матчасть, то чего даете общие советы?
Удалитьвот вы пишите
"И не забывать за балансировку данных." - вообще то для справки вам сообщаю: автор поста сделал up и under samling - поэтому с вашей стороны стоило бы прокомментировать результаты.
И если уж вы знаете матчасть, то тогда читайте внимательно посты.
И если вы знаете про предпосылки лог регрессии - расскажите нам про эти предпосылки
Желательно со ссылкой на источник - мне самому это интересно
Интересно, где в посте написано, что была сделана балансировка данных?
УдалитьОбычные предпосылки, что лог регрессия покажет хороший результат - это то, что данные содержат большое количество количественных предикторов и мало факторных, так как с большим количеством факторных переменных лог регрессия работает слабее. Источников здесь не будет, это лишь мое мнение и возможно мнение некоторых аналитиков на просторе интернета.
Вы уверены, что корректно проводить переписку в таком тоне с незнакомым человеком, который из чистого "преподавательского" желания комментирует здесь и хоть немного разбавляет затишье в комментариях?
По возможности, я хотел бы общаться больше с автором поста, чтобы он решал о пользе моих советов, спасибо.
мне совершенно неважно, кто вы и откуда.
УдалитьОсобенно, если вы не умеете читать чужие тексты. Да, про балансировку было написано через жопу, но и это надо заметить, тем более, что вы как бы советуете автору поста, то должны подмечать такие особенности.
И я уверен в одном: если коммент не несет никакой ценности, то нахрен он здесь нужен. Вы, конечно, не согласитесь с этим, ага. Можете учить в академии ДТЭК, в чем вопрос?
Про лог регрессию опять же я вам скажу, что есть вполне обоснованное мнение, я могу привести источники
Совет же был не вам дан, так не надо решать несет он ценность или нет. Не ваши же "ляпы" обсуждают.
УдалитьК тому же, как я уже говорил выше, с вами нет никакого желания общаться. Мало того, что вы абсолютно не интересны для меня как "эксперт", так еще и адекватно общаться не умеете. Поэтому или просто не отвечайте на мои сообщения или не публикуйте мои комментарии, как делали раньше с комментариями с критикой в других постах, где вы от кого-то требовали нормального распределения на большой выборке данных для использования теста Стъюдента или когда говорите за BigData, когда ее и в помине нет.
Я не знаю, про что вы говорите, но я не публикую комментарий часто в случае, если он откровенную хрень несет.
УдалитьЕсли я вам абсолютно не интересен как "эксперт", то че сюда ходите? тем более уже давно я вам не интересен как "эксперт".
Реализуйте себя на своей площадке.
Создайте свой блог, в котором напишите с цитатой, что вот Бабушкин никакой не эксперт, а мудак. И докажите это.
В чем проблема?
Я лично так и делаю.
Давайте про ваш коммент.
Цитирую лословно
"Хотелось бы посмотреть на корреляционную матрицу. Также, учитывая специфику предикторов и датасета в целом, скорее всего randomforest не будет здесь хорошо себя показывать. Рекомендую попробовать алгоритмы glm, gam и xgb, и сравнить результаты.
И не забывать за балансировку данных."
Если вы хотите донести мысль до автора, то надо как минимум пояснить, что вы имеете ввиду.
Вы же изобразили из себя этакого эксперта, который предлагает делать, потому что так нужно.
А написать надо было одну фразу с пояснением.
И давайте уже на этом закончим: конструктива в нашем общении точно больше не будет
"И давайте уже на этом закончим: конструктива в нашем общении точно больше не будет"
УдалитьСогласен
Олег, т.е. я жду от вас поста в своем блоге, где вы покажете всем, какой я "эксперт", верно?
УдалитьВы там ссылались на какой то мой пост, где я там что то неверно писал. У Вас есть прекрасная возможность показать рынку, какой я "эксперт".
Со своей стороны обещаю вам впредь публикацию ваших комментов только в случае, если они, на мой взгляд, будут нести ценность - уж простите, я владелец блога и сам принимаю решение, что публиковать, а что нет
ну и спасибо за дискуссию) и за "эксперта")))
УдалитьАлександр, а у вас up и under sampling посчитан для train или test set?
ОтветитьУдалитьПолучается на train. Думаю, что стоит всё-таки спросить на коде, в mlr мы же это делаем через эти команды: rforest.over, rforest.under. И видим результаты и для up, и для down. У меня стали сомнения появляться.
Удалитьв чем вопрос?
Удалитьrforest.over - это просто название модели для up sampling
rforest.under - для under sampling
на коде лучше в группе тогда
Коллеги вообще всем спасибо за обратную связь.
ОтветитьУдалить