Хочу познакомить с важным материалом и крайне интересным hr-аналитиком.
Pasha Roberts был уже представлен в моем блоге, см. Кейс по оценке эффективности подбора и адаптации персонала или тоже самое, но в режиме видеолекции на английском Video: Data Science for Workforce Optimization: Reducing Employee Attrition.
Но поскольку память человеческая недолговечна, представляю еще раз: Pasha Roberts был спецом по электронному обучению, переквалифицировался в hr-аналитики, сейчас делает потрясающие предиктивные модели, при этом делится знаниями.
Я у него многому научился, даю очень схожие вещи, см. Прогноз индивидуального дожития и тюнинг параметров регрессии Кокса в пакете mlr, даю это на своем семинаре по R Семинар-практикум "HR-Аналитика в R", но поскольку нет пророка в своем отечестве, западного гуру вы будете слушать с бОльшим интересом.
Обратите внимание на слайд № 22 "Don't use logistic methods to predict attrition". Это к вопросу о том, какие модели должны быть в прогнозе текучести. На Конференция по hr-аналитике журнала Штат 05.07.2017 было два кейса, которые вполне можно отнести к машинному обучению и которые были про одно и тоже - прогноз текучести персонала. И логика кейсов на 100 % совпадала: разница была только в том, что в первом кейсе (компания КПМГ) считали вероятность того, что сотрудник отработает меньше / больше одного года в компании, а во втором кейсе от Делойт считали вероятность, что сотрудник отработает меньше / больше двух лет. И алгоритм в кейсах был стандартный - xgboost.
А Pasha Roberts пишет о том, что задачи классификации в принципе не стоит использовать в прогнозе текучести персонала. И я с ним согласен.
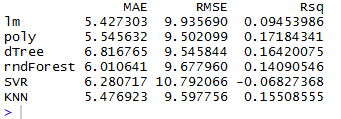
Безусловно, не стоит доверять вот просто так на словах, считайте свои цифры сами. В любом случае рекомендую ознакомиться с презентацией - она включает в себя куски кода, методологию анализа, представление результатов.
Поскольку славное российское государство лишило нас возможности работы на Линкедин (а slideshare - ресурс Линкедин), то у многих из вас презентация не откроется у меня в блоге, по этой причине даю прямую ссылку на презентацию How to use Survival Analytics to predict employee turnover - попробуйте скачать ее.
На этом все, читайте нас в фейсбуке
Pasha Roberts был уже представлен в моем блоге, см. Кейс по оценке эффективности подбора и адаптации персонала или тоже самое, но в режиме видеолекции на английском Video: Data Science for Workforce Optimization: Reducing Employee Attrition.
Но поскольку память человеческая недолговечна, представляю еще раз: Pasha Roberts был спецом по электронному обучению, переквалифицировался в hr-аналитики, сейчас делает потрясающие предиктивные модели, при этом делится знаниями.
Я у него многому научился, даю очень схожие вещи, см. Прогноз индивидуального дожития и тюнинг параметров регрессии Кокса в пакете mlr, даю это на своем семинаре по R Семинар-практикум "HR-Аналитика в R", но поскольку нет пророка в своем отечестве, западного гуру вы будете слушать с бОльшим интересом.
Обратите внимание на слайд № 22 "Don't use logistic methods to predict attrition". Это к вопросу о том, какие модели должны быть в прогнозе текучести. На Конференция по hr-аналитике журнала Штат 05.07.2017 было два кейса, которые вполне можно отнести к машинному обучению и которые были про одно и тоже - прогноз текучести персонала. И логика кейсов на 100 % совпадала: разница была только в том, что в первом кейсе (компания КПМГ) считали вероятность того, что сотрудник отработает меньше / больше одного года в компании, а во втором кейсе от Делойт считали вероятность, что сотрудник отработает меньше / больше двух лет. И алгоритм в кейсах был стандартный - xgboost.
А Pasha Roberts пишет о том, что задачи классификации в принципе не стоит использовать в прогнозе текучести персонала. И я с ним согласен.
Безусловно, не стоит доверять вот просто так на словах, считайте свои цифры сами. В любом случае рекомендую ознакомиться с презентацией - она включает в себя куски кода, методологию анализа, представление результатов.
Поскольку славное российское государство лишило нас возможности работы на Линкедин (а slideshare - ресурс Линкедин), то у многих из вас презентация не откроется у меня в блоге, по этой причине даю прямую ссылку на презентацию How to use Survival Analytics to predict employee turnover - попробуйте скачать ее.
Понравился пост?
и Вы захотите выразить мне благодарность, просто покликайте на директ рекламу ниже на странице - у вас это отнимет несколько секунд, а мне принесет немного денег.На этом все, читайте нас в фейсбуке