После семинара по R участники делают свои проекты - домашние задания. Я тоже решил сделать свое домашнее задание. Чтобы показать студентам, что я сам еще могу руками работать. И еще показать потенциальным участникам семинара "HR-аналитика в R", что их ждет на семинаре. Если Вы не аналитик, рекомендую Вам в самом низу почитать менеджерскую часть проекта - то, что делает менеджер, принимающий решения, на основе анализа.
В качестве задачи я решил взять задачу про прогноз успешности адаптации персонала (мы на семинаре разбирали такую задачу), но решить ее с помощью пакета mlr.
mlr - это фреймфорк, пакет обертка для алгоритмов машинного обучения, он значительно облегчает жизнь специалистам по машинному обучению. До последнего времени я пользовался пакетом caret, его же использую на семинаре. Но вот в качестве собственного развития покажу, как работает mlr
Если помните, в caret мы настраиваем только параметр cp.
Вернемся к случайному лесу. Сначала зададим учителя - сам алгоритм
Задаем кросс валидацию
И полученное качество модели (мы указали measures = auc, auc - площадь под кривой, но можно указать любую другую меру оценки качества модели):
Поскольку выборка у нас разбалансирована: класс "1" в трейн сете 1080, а класс "0" - 514, применим технику работы с такими данными - over- and undersampling (обращаю внимание, я показываю simple over- and undersampling, есть более продвинутые техники, см. Imbalanced Classification Problems
Задаем полученные гиперпараметры для моделей
Посмотрим на полученное качество моделей на тест сете (покажу код только на примере основного датасета, и в данном случае опять использую mlr:: , потому что в caret есть также команда performance)
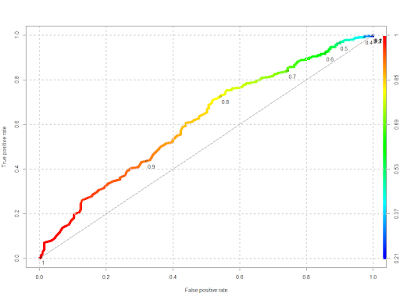 Не густо
Не густо
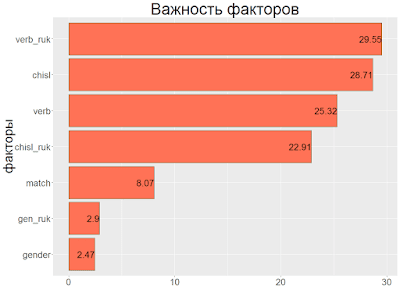 Забавно, но прохождение адаптации зависит от руководителя как минимум не меньше, чем от самого подчиненного.
Забавно, но прохождение адаптации зависит от руководителя как минимум не меньше, чем от самого подчиненного.

Мы с вами прогнозируем, пройдет ли кандидат адаптационный период, а не отбираем кандидатов в отряд космонавтов, поэтому наше решение на графике precision recall curve должно быть скорее справа, чем слева: нам надо набрать больше людей. В этой ситуации кажется наиболее комфортным решением с границей 0.8
FALSE TRUE
0 93 110
1 132 348
Жесть, правда? Мы отсекаем почти половину не очень хороших кандидатов 93 / (93+110), но при этом отсекаем почти треть потенциально хороших кандидатов 132 / (132+348).
Сделаем меньше границу? 0, 7
FALSE TRUE
0 53 150
1 77 403
При такой границе принятия решения мы отсекаем примерно каждого четвертого неуспешного кандидата и каждого шестого успешного. И если у нас в среднем проходило успешно испытательный срок 68 % кандидатов, то при внедрении алгоритма мы дадим бизнесу 73 % кандидатов, которые пройдут испытательный срок. Итого, мы выигрываем 5 %, это снижение затрат на обучение, зарплату и т.д... Но в минусе - работа спеца по аналитике (это не самое дорогое), а также увеличение затрат на подбор, потому что трафик кандидатов надо будет увеличить примерно на четверть - 25 %. Это может оказаться дороже.
Поэтому вопрос, внедрять данную систему отбора или нет, надо после ответа на два вопроса:
На этом все, читайте нас в фейсбуке
В качестве задачи я решил взять задачу про прогноз успешности адаптации персонала (мы на семинаре разбирали такую задачу), но решить ее с помощью пакета mlr.
mlr - это фреймфорк, пакет обертка для алгоритмов машинного обучения, он значительно облегчает жизнь специалистам по машинному обучению. До последнего времени я пользовался пакетом caret, его же использую на семинаре. Но вот в качестве собственного развития покажу, как работает mlr
Итак,
library(mlr)
Сразу обозначу, почему mlr мне показался симпатичен- параметры модели. И возьму один из самых популярных алгоритмов - случайный лес. Но количество алгоритмов больше, в том числе любимый всеми xgboost
Это параметры модели. Больше, чем в caret. Для дерева решений параметры такиеgetParamSet("classif.randomForest")
Type len Def Constr Req Tunable Trafo ntree integer - 500 1 to Inf - TRUE - mtry integer - - 1 to Inf - TRUE - replace logical - TRUE - - TRUE - classwt numericvector- 0 to Inf - TRUE - cutoff numericvector - 0 to 1 - TRUE - strata untyped - - - - FALSE - sampsize integervector - 1 to Inf - TRUE - nodesize integer - 1 1 to Inf - TRUE - maxnodes integer - - 1 to Inf - TRUE - importance logical - FALSE - - TRUE - localImp logical - FALSE - - TRUE - proximity logical - FALSE - - FALSE - oob.prox logical - - - Y FALSE - norm.votes logical - TRUE - - FALSE - do.trace logical - FALSE - - FALSE - keep.forest logical - TRUE - - FALSE - keep.inbag logical - FALSE - - FALSE -
getParamSet("classif.rpart")
Type len Def Constr Req Tunable Trafo minsplit integer - 20 1 to Inf - TRUE - minbucket integer - - 1 to Inf - TRUE - cp numeric - 0.01 0 to 1 - TRUE - maxcompete integer - 4 0 to Inf - TRUE - maxsurrogate integer - 5 0 to Inf - TRUE - usesurrogate discrete - 2 0,1,2 - TRUE - surrogatestyle discrete - 0 0,1 - TRUE - maxdepth integer - 30 1 to 30 - TRUE - xval integer - 10 0 to Inf - FALSE - parms untyped - - - - TRUE -
Если помните, в caret мы настраиваем только параметр cp.
Вернемся к случайному лесу. Сначала зададим учителя - сам алгоритм
rf = makeLearner("classif.randomForest", predict.type = "prob", par.vals = list(ntree = 200, mtry = 3, importance = TRUE))
Обратите внимание, я сразу задаю тип прогноза вероятность, а не класс, чтобы можно было играться границами принятия решения. Если вы хотите предсказывать класс, указываете "response". И самое вкусное - задаем тюнинг гиперпараметров rf_param = makeParamSet(
makeIntegerParam("ntree",lower = 50, upper = 500),
makeIntegerParam("mtry", lower = 1, upper = 6),
makeIntegerParam("nodesize", lower = 10, upper = 50)
)
rancontrol = makeTuneControlRandom(maxit = 50L)<- makeparamset="" p=""> <- maketunecontrolrandom="" maxit="50L)</p">
mtry у меня небольшой, потому что всего 6 переменных в уравнении.Задаем кросс валидацию
set_cv = makeResampleDesc("RepCV", folds = 10L, reps = 5L)
Прежде, чем перейти к тренировке параметров, скажу, что в mlr развита функция препроцессинга, вы можете делать импутацию, нормализацию и feature selection. Я это не показываю здесь, потому что импутация и feature selection не нужна для моего датасета, тем более это сильно раздует пост, а вот скейлинг я привык делать с помощьюrange01 = function(x){(x-min(x))/(max(x)-min(x))
И на вход мы подаем не dataframe, а класс Task - это по сути одна строка кода
trainTask = makeClassifTask( data = train,target = "ef") testTask = makeClassifTask(data = test,target = "ef")Где train и test - это наш разбитый на две подвыборки датасет, а ef - целевая переменная. В нашем случае это показатель проходимости срока адаптации: 1 - прошел срок адаптации, 0 - не прошел. Запускаем тюнинг
rf_tune = tuneParams(learner = rf, resampling = set_cv, task = trainTask, par.set = rf_param, control = rancontrol, measures = auc)Количество параметров, итераций и фолдов кросс валидации с повторениями позволяет мне поставить чай, заварить пакетик и пофилософствовать. После посмотрим на best гиперпараметры
rf_tune$x $ntree [1] 366 $mtry [1] 2 $nodesize [1] 37
И полученное качество модели (мы указали measures = auc, auc - площадь под кривой, но можно указать любую другую меру оценки качества модели):
rf_tune$y auc.test.mean 0.615503Прямо скажем, не очень хороший показатель. Ну а что вы хотели? Эти данные реальные, не из учебника.
Поскольку выборка у нас разбалансирована: класс "1" в трейн сете 1080, а класс "0" - 514, применим технику работы с такими данными - over- and undersampling (обращаю внимание, я показываю simple over- and undersampling, есть более продвинутые техники, см. Imbalanced Classification Problems
task.over = oversample(trainTask, rate = 2) task.under = undersample(trainTask, rate = 1/2)И если наш датасет имел соотношение классов 514 / 1080, то для новых выборок получаем
table(getTaskTargets(task.over)) 0 1 1028 1080 table(getTaskTargets(task.under)) 0 1 514 540Т.е. в первом случае мы увеличили число не прошедших испытательный срок, во втором - уменьшили количество прошедших. И запускаем тюнинг параметров для этих выборок. И получаем метрики качества для обеих выборок
rf_tune.over$y auc.test.mean 0.7951566 rf_tune.under$y auc.test.mean 0.6162755Чувствуется разница? Площадь под кривой 0, 795 для оверсемплинга.
Задаем полученные гиперпараметры для моделей
rf.tree = setHyperPars(rf, par.vals = rf_tune$x) rf.tree.over =setHyperPars(rf, par.vals = rf_tune.over$x) rf.tree.under = setHyperPars(rf, par.vals = rf_tune.under$x)И обучаем трейн датасет с полученными параметрами
rforest = mlr::train(rf.tree, trainTask) rforest.over = mlr::train(rf.tree.over, task.over) rforest.under = mlr::train(rf.tree.under, task.under)mlr:: в данном коде - последствие того, что я запустил с mlr одновременно caret - машина ругается и выдает ошибку.
Посмотрим на полученное качество моделей на тест сете (покажу код только на примере основного датасета, и в данном случае опять использую mlr:: , потому что в caret есть также команда performance)
performance(predict(rforest, newdata = test), measures = auc)
auc = 0.6105039 auc.over = 0.6209616 auc.under = 0.6045515Вывод: в нашем случае техники работы с несбалансированными выборками не дали эффекта. Ну и сама по себе модель слабая, что ставит вопрос о ее пркатической применимости.
ROC curve

Важность факторов
getFeatureImportance(rforest)Я не нашел в пакете mlr средств визуализации, но из полученной важности факторов формулы выше сами делаем график

И самое важное
А можем ли мы полученные результаты применять на практике? Здесь уже должен включаться менеджер, а не специалист по машинномуобучению
FALSE TRUE
0 93 110
1 132 348
Жесть, правда? Мы отсекаем почти половину не очень хороших кандидатов 93 / (93+110), но при этом отсекаем почти треть потенциально хороших кандидатов 132 / (132+348).
Сделаем меньше границу? 0, 7
FALSE TRUE
0 53 150
1 77 403
При такой границе принятия решения мы отсекаем примерно каждого четвертого неуспешного кандидата и каждого шестого успешного. И если у нас в среднем проходило успешно испытательный срок 68 % кандидатов, то при внедрении алгоритма мы дадим бизнесу 73 % кандидатов, которые пройдут испытательный срок. Итого, мы выигрываем 5 %, это снижение затрат на обучение, зарплату и т.д... Но в минусе - работа спеца по аналитике (это не самое дорогое), а также увеличение затрат на подбор, потому что трафик кандидатов надо будет увеличить примерно на четверть - 25 %. Это может оказаться дороже.
Поэтому вопрос, внедрять данную систему отбора или нет, надо после ответа на два вопроса:
- Можем ли мы собрать и использовать в модели дополнительную информацию о кандидатах, которая могла бы улучшить качество модели?
- Будет ли выигрыш затрат на обучение / зарплату и т.п. вновь принятых выше, чем косты, связанные с увеличением затрат на подбор?
Понравился пост?
и Вы захотите выразить мне благодарность, просто покликайте на директ рекламу ниже на странице - у вас это отнимет несколько секунд, а мне принесет немного денег.На этом все, читайте нас в фейсбуке
Комментариев нет:
Отправить комментарий