Анализирую анкеты обратной связи по корпоративным семинарам. В анкетах помимо полей с цифровой оценкой семинаров есть поле обратной связи в виде открытого вопроса, участники могли писать про пройденный семинар все, что хотели.
В данном посте публикую подход к анализу, если заинтересуетесь, готов его обсуждать.
Первым заходом на решение проблемы была попытка построить кластеры отзывов: т.е. попытаться превратить все море тестовых отзывов превратить в несколько групп, связанных по смыслу. Выделю эти группы:
 На картинке показана попытка разделить все отзывы на три кластера, качество модели настолько качественно, насколько кластеры отделены друг от друга.
На картинке показана попытка разделить все отзывы на три кластера, качество модели настолько качественно, насколько кластеры отделены друг от друга.
Видно, что кластер 0 не существует практически, а кластеры 1 и 2 это если и не один кластер, то граница весьма условна. Причем, это видно по смысловому наполнению, когда слова "материал" или "тренер" содержаться во всех кластерах, что значит для нас, мы не смогли поделить отзывы по нужным нам смыслам.
Но я таким образом могу посчитать насколько каждый отзыв участника семинара / тренинга схож с эталонным сообщением, сообщением, который отражает нужный нам набор слов.
Например, я беру тему "Материалы семинара" и создаю набор слов, выражений:
"раздатка восприятие визуализировать наглядный раздаточный материал материалы ....".
Далее запускаю алгоритм машинного обучения, который определяет меру сходства каждого сообщения с этим эталонным. И каждое сообщение получает свою оценку сходства, которую я записываю отдельной переменной. У нас получается вот такая картина:
В данном посте публикую подход к анализу, если заинтересуетесь, готов его обсуждать.
Проблема
проблема использования подобных вопросов очевидна:- пишут редко, т.е. вообще отзывов мало;
- а в имеющихся отзывах мало содержательной информации, в основном: "все было супер", "препод молодец!";
- И когда мы вытаскиваем наконец содержательные отзывы, например, про полноту и ясность раздаточного материала, то непонятно, является ли это субъективным мнением одного участника или отражает мнение хоть части группы. Потому что, если это субъективная оценка участника, то реагировать и работать надо с участником, а если отражает мнение, то работать надо с преподавателем / тренером.
- А теперь с учетом всего вышесказанного мы выходим на главную проблему: и кто после этого будет читать эти анкеты? Тренинг менеджер компании потратит два часа времени на чтение анкет, но сделать реальных выводов не сможет.
Решение
Неспециалистов сразу предупреждаю, что будут какие-то термины в области машинного обучения, которые могут показаться темным лесом, можно перейти сразу к результатам.Первым заходом на решение проблемы была попытка построить кластеры отзывов: т.е. попытаться превратить все море тестовых отзывов превратить в несколько групп, связанных по смыслу. Выделю эти группы:
- раздаточный материал семинара;
- тренер;
- применимость полученных знаний на практике;
- организация семинара.

Видно, что кластер 0 не существует практически, а кластеры 1 и 2 это если и не один кластер, то граница весьма условна. Причем, это видно по смысловому наполнению, когда слова "материал" или "тренер" содержаться во всех кластерах, что значит для нас, мы не смогли поделить отзывы по нужным нам смыслам.
Мера сходства сообщений.
Тогда я решил использовать меру сходства сообщений. Это почти тоже самое, что поисковая выдача: первым в поисковике выходит наиболее релевантное сообщение, а потом по мере убывания. Понятно, что Гугл и Яндекс делают это сложнее)))Но я таким образом могу посчитать насколько каждый отзыв участника семинара / тренинга схож с эталонным сообщением, сообщением, который отражает нужный нам набор слов.
Например, я беру тему "Материалы семинара" и создаю набор слов, выражений:
"раздатка восприятие визуализировать наглядный раздаточный материал материалы ....".
Далее запускаю алгоритм машинного обучения, который определяет меру сходства каждого сообщения с этим эталонным. И каждое сообщение получает свою оценку сходства, которую я записываю отдельной переменной. У нас получается вот такая картина:
благодаря грамотный тренер группа
активно участвовать замечательный живой яркий динамичный следить
|
1.41
|
тема форма подача информация изучить
разобрать инструмент реализация личный цель
|
1.36
|
не обращайте внимание на "нерусский" текст, я его предобработал (убрал лишние слова, привел все в одну форму), поэтому он как бы не читаем.
Но зато вы видите, что у одного отзыва стоит оценка 1, 41, у другого 1, 36. У того, что 1, 36 мы видим слово "подача", которое было приведено в эталонном сообщении. Поэтому данный отзыв имеет больше сходства с эталонным. И важный момент: мера сходства показывает не просто количество слов из эталонного сообщения, но относительную частоту, т.е. сколько слов эталонного сообщения по отношению к количеству всего слов в сообщении. Мы тем самым вводим вес этой темы для отзыва, т.е. учитываем, что если участникам написал только про материалы семинара, вес этого сообщения будет более значимым.
Таким образом мы можем посчитать средние значения по каждому семинару / тренингу. Получается вот что.
Семинар
|
Среднее значение меры сходства
|
|
1
|
Личная эффективность
|
1.403539
|
2
|
Навыки проведения презентации
|
1.398800
|
3
|
Навыки коммуникации
|
1.404731
|
4
|
Переговоры
|
1.403366
|
У нас максимальное различие определяется оценкой 1, 41. И таблица может ввести нас в удрученное состояние:
- слишком близки средние значения к 1,4 1
- слишком невелико различие между средними.
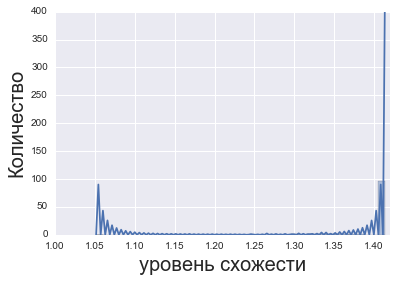
Но давайте посмотрим на распределение оценок.

Упс, у нас из 2853 анкет более 75 % вообще никак не связаны с нашим эталонным сообщением (это правый столбец на картинке, оно же значение 1, 41). И это нормально. Ну никак тема материалов семинара не затронула участников. В этом же числе отзывов и пустые отзывы.
Дескриптивные статистики
count 2853.000000 mean 1.403738 std 0.032555 min 1.051462 25% 1.414214 50% 1.414214 75% 1.414214 max 1.414214
Что мы делаем
Тем не менее, четверть отзывов так или иначе связана с темой материалов. И нам осталось понять, есть ли значимые различия в оценках средних значений семинара по теме "Материалы семинара".
А это может сделать уже любой выпускник психфака, прошедший курс тервера и матстатистики. С помощью критерия Крускала и Краскелла Уолисса.
KruskalResult(statistic=15.880403258075576, pvalue=0.0011998352099500508)
Значимость критерия ниже необходимого нам уровня в 0, 05 и даже в 0, 01, поэтому мы можем утверждать, что на семинаре "Навыки проведения презентации" тема материалов семинара поднималась в отзывах участников значимо чаще. Отсюда следующие шаги:
- мы проводим анализ тональности текста (отвечаем на вопрос, были ли эти отзывы чаще позитивными или негативным);
- даем обратную связь тренеру / преподавателю или принимаем решение о дальнейшей работе с ним.
Все. От профи по машинному обучению хочу услышать предложения, как можно сделать проще то, что я понаделал. Ибо я только начинаю тут шаги делать, а от коллег по HR хотелось бы услышать про перспективы применимости услышать. Спасибо.
Понравился пост?
если Вы захотите выразить мне благодарность за интересный пост, вы можете перевести небольшую сумму мне на Яндекс кошелек (кликните по кнопке Перевести)
или сделать перевод на карту Сбербанка,
Номер карты 676 280 38 921 538 46 57
Или просто покликайте на директ рекламу ниже на странице - у вас это отнимет несколько секунд, а мне принесет немного денег.
спасибо!
Комментариев нет:
Отправить комментарий