В подборе/ прогнозе эффективных руководителей компании есть одна важная проблема, которую раньше как-то обходили стороной.
Представьте, что вы взяли всех руководителей компании, поделили на эффективных и остальных, взяли результаты их тестов и установили, что руководители с высокими показателями по вербальному интеллекту имеют больше шансов быть эффективными.
Хороший результат, ура!
На самом деле, не совсем ура. Потому что мы не будем теперь вычленять всех работников компании с высокими показателями по интеллекту и смотреть их на позицию руководителя.
Как минимум есть одно ограничение: если человек имеет высокий интеллект, но работает три недели в компании (или даже три месяца), то его даже в лучшей фантазии не назначат руководителем.
Следовательно нашему анализу не хватает простой вещи: мы должны назначать не просто на основе интеллекта, а с учетом дозревания до позиции руководителя.
И пример такого анализа я хочу показать

На картинке: по оси X показан стаж работы кандидата в руководители: от момента трудоустройства в компании до момента назначения на должность.
Красным обозначена вероятность попадания в эффективные руководители, черным - в остальные.
Обратите внимание, что в крайней правой точке черная кривая достигает значения 60, а красная - 40. Это и есть наше распределение на эффективных и неэффективных, т.е. у нас некий средний кандидат в итоге имеет вероятность 40 % стать успешным.
ИЛИ, по другому: стать эффективным руководителем шансы в 1,5 раза меньше, чем другим (60/40 = 1,5). Это ключевой момент для понимания.
 Теперь давайте смоделируем ситуацию для кандидата с высоким и низким интеллектом.
Теперь давайте смоделируем ситуацию для кандидата с высоким и низким интеллектом.

Я думаю, что здесь совершенно очевидно понятно, на какой диаграмме кандидат с высоким, на какой - с низким интеллектом. Заметно, что кандидаты с низким интеллектом почти не имеют шансов, а вот у кандидатов с высоким интеллектом картина интересная: они эффективней, если их брать в руководители раньше, а с момента, когда стаж превышает 100 с небольшим отрезков времени, интеллект как конкурентное преимущество исчерпывает себя. Видимо, начинают сказываться связи в компании, опыт и т.п...
Или вот еще более интересная зависимость


Слева - вероятность стать эффективным / неэффективным при низких показателях по качеству N личностного опросника.
И все логично, а справа картина вероятностей в ситуации, когда у кандидата высокие показатели. получается, что кандидат вырывает себе ничью (потому что в итоге у него шансы 50/50 только на стаже в 150 временных отрезков.
И обратите внимание: у нас итоговая вероятность в лучшем случае составляет 50 / 50. Что это значит? Это значит, что мы улучшаем прогноз только за 10 %. Т.е. у нас базовое распределение лучших и остальных 40 на 60, а мы в случае, например, кандидата с высокими показателями по интеллекту и личностному качеству получаем вот такую картинку

Т.е. при любом стаже вероятность попадания в эффективные и неэффективные руководители у нас 50/50. Кому то это может показаться плохой точностью так и есть, но помните, что мы в любом случае улучшаем модель, поскольку у нас при нашей существующей политике отбора руководителей точность равна 40 / 60, и мы увеличиваем точность на 10 %.
Представьте, что вы взяли всех руководителей компании, поделили на эффективных и остальных, взяли результаты их тестов и установили, что руководители с высокими показателями по вербальному интеллекту имеют больше шансов быть эффективными.
Хороший результат, ура!
На самом деле, не совсем ура. Потому что мы не будем теперь вычленять всех работников компании с высокими показателями по интеллекту и смотреть их на позицию руководителя.
Как минимум есть одно ограничение: если человек имеет высокий интеллект, но работает три недели в компании (или даже три месяца), то его даже в лучшей фантазии не назначат руководителем.
Следовательно нашему анализу не хватает простой вещи: мы должны назначать не просто на основе интеллекта, а с учетом дозревания до позиции руководителя.
И пример такого анализа я хочу показать
Итак
У нас есть 100 руководителей, 40 из которых признаны эффективными, а 60 среднего уровня (беру с потолка цифры просто для примера).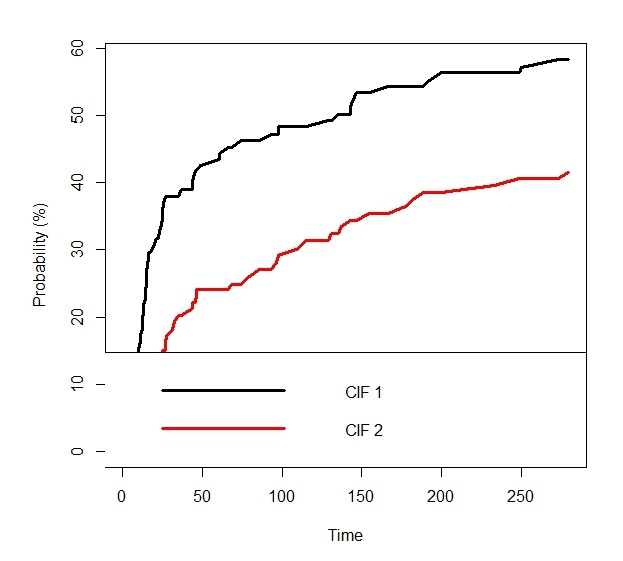
Красным обозначена вероятность попадания в эффективные руководители, черным - в остальные.
Обратите внимание, что в крайней правой точке черная кривая достигает значения 60, а красная - 40. Это и есть наше распределение на эффективных и неэффективных, т.е. у нас некий средний кандидат в итоге имеет вероятность 40 % стать успешным.
ИЛИ, по другому: стать эффективным руководителем шансы в 1,5 раза меньше, чем другим (60/40 = 1,5). Это ключевой момент для понимания.
 Теперь давайте смоделируем ситуацию для кандидата с высоким и низким интеллектом.
Теперь давайте смоделируем ситуацию для кандидата с высоким и низким интеллектом.
Я думаю, что здесь совершенно очевидно понятно, на какой диаграмме кандидат с высоким, на какой - с низким интеллектом. Заметно, что кандидаты с низким интеллектом почти не имеют шансов, а вот у кандидатов с высоким интеллектом картина интересная: они эффективней, если их брать в руководители раньше, а с момента, когда стаж превышает 100 с небольшим отрезков времени, интеллект как конкурентное преимущество исчерпывает себя. Видимо, начинают сказываться связи в компании, опыт и т.п...
Или вот еще более интересная зависимость


Слева - вероятность стать эффективным / неэффективным при низких показателях по качеству N личностного опросника.
И все логично, а справа картина вероятностей в ситуации, когда у кандидата высокие показатели. получается, что кандидат вырывает себе ничью (потому что в итоге у него шансы 50/50 только на стаже в 150 временных отрезков.
И обратите внимание: у нас итоговая вероятность в лучшем случае составляет 50 / 50. Что это значит? Это значит, что мы улучшаем прогноз только за 10 %. Т.е. у нас базовое распределение лучших и остальных 40 на 60, а мы в случае, например, кандидата с высокими показателями по интеллекту и личностному качеству получаем вот такую картинку

Т.е. при любом стаже вероятность попадания в эффективные и неэффективные руководители у нас 50/50. Кому то это может показаться плохой точностью так и есть, но помните, что мы в любом случае улучшаем модель, поскольку у нас при нашей существующей политике отбора руководителей точность равна 40 / 60, и мы увеличиваем точность на 10 %.
Понравился пост?
если Вы захотите выразить мне благодарность за интересный пост, вы можете перевести небольшую сумму мне на Яндекс кошелек (кликните по кнопке Перевести)
или сделать перевод на карту Сбербанка,
Номер карты 676 280 38 921 538 46 57 - укажите "пост в блоге".
Или просто покликайте на директ рекламу ниже на странице - у вас это отнимет несколько секунд, а мне принесет немного денег.
спасибо!
Комментариев нет:
Отправить комментарий