четверг, 17 марта 2016 г.
вторник, 15 марта 2016 г.
Прогностичная ценность (важность) шкал теста CPI в отборе эффективных работников
Кейс, который уже всем надоел: у нас есть 87 работников, которые при приеме на работу прошли тест CPI, которые впоследствии были причислены к условным "звездам" и "не звездам" (очень эффективным и остальным).
Задача сводится к использованию теста CPI при отборе эффективных работников. Сразу сообщаю, что тупо использовать результаты нельзя у вас в компаниях, надо обязательно все процедуры повторять, однако тест будет интересен содержательно.
Кратко напомню онтологию анализа.
Линейные методы типа логистической регрессии давали такую картинку (см. подробней Отбираем "звезд" на этапе подбора с помощью тестов)
 Лошистическая регрессия отбирала три шкалы: Sp, Fx, Lp - причем вес в порядке убывания, т.е. Sp самый важный фактор.
Лошистическая регрессия отбирала три шкалы: Sp, Fx, Lp - причем вес в порядке убывания, т.е. Sp самый важный фактор.
Дерево решений давало два фактора Sp, Fx, - и важность та же. Точность моделей при этом не превышала 80 %
Ну и кстати обратите на рисунок, границы достаточно четкие, но в случае шкалы Sp м должны пойти на компромисс, проводя границу. Чаще всего машинка проводила границу по 56 баллам Sp. Т.е. мы жертвуем эффективными работниками, но отсекаем больше не эффективных.
Но кто сказал, что границы должны быть прямыми? У нас есть непараметрические алгоритмы решения данной задачи, которые прописывают границы очень гибко (см. О границах принятия решения по кандидату).

Точность модели вырастает до 90 %.
И эти самые непараметрические алгоритмы так расставляют важность шкал в отборе
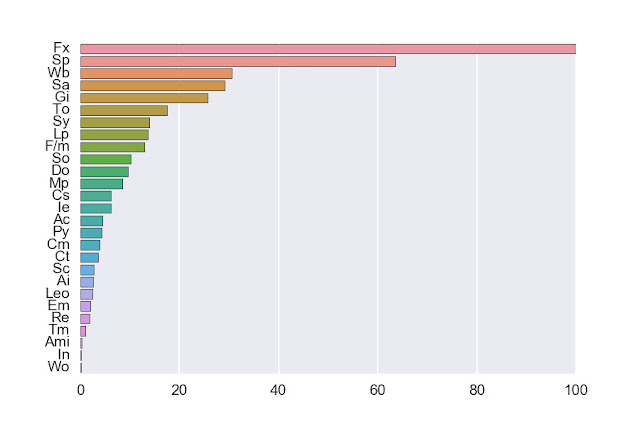 Обратите внимание, что шкала Fx оказалась в этом алгоритме важнее Sp на треть. Приятно, что эти две шкалы являются самыми объясняющими, но работают не только они.
Обратите внимание, что шкала Fx оказалась в этом алгоритме важнее Sp на треть. Приятно, что эти две шкалы являются самыми объясняющими, но работают не только они.
Ну и хватит. напомню, что в Вашей компании список значимых шкал и их вес может быть совсем другим, если вообще CPI позволит что-либо дифференциировать.
Удачи в отборе "pdtpl@
Задача сводится к использованию теста CPI при отборе эффективных работников. Сразу сообщаю, что тупо использовать результаты нельзя у вас в компаниях, надо обязательно все процедуры повторять, однако тест будет интересен содержательно.
Кратко напомню онтологию анализа.
Линейные методы типа логистической регрессии давали такую картинку (см. подробней Отбираем "звезд" на этапе подбора с помощью тестов)
Дерево решений давало два фактора Sp, Fx, - и важность та же. Точность моделей при этом не превышала 80 %
Ну и кстати обратите на рисунок, границы достаточно четкие, но в случае шкалы Sp м должны пойти на компромисс, проводя границу. Чаще всего машинка проводила границу по 56 баллам Sp. Т.е. мы жертвуем эффективными работниками, но отсекаем больше не эффективных.
Но кто сказал, что границы должны быть прямыми? У нас есть непараметрические алгоритмы решения данной задачи, которые прописывают границы очень гибко (см. О границах принятия решения по кандидату).

И эти самые непараметрические алгоритмы так расставляют важность шкал в отборе

- Fx (гибкость). Для определения степени гибкости и адаптабельности индивидуального мышления и социального поведения. Низкие оценки: Осмотрительный, осторожный, надоедливый, трудолюбивый, сдержанный, вежливый, методичный и ригидный; с формальным и педантичным мышлением; относящийся со слишком большим уважением к авторитетам, обычаям и традициям.
- Sp (социальный облик). Для оценки таких факторов, как манера держаться, спонтанность и самоуверенность в личных и социальных взаимоотношениях. Высокие оценки: Умный, полный энтузиазма, с богатым воображением, проворный, неформальный, спонтанный и разговорчивый, обладающий экспрессивной, кипучей натурой.
- Wb (чувство благополучия). Для идентификации лиц, склонных минимизировать свои неприятности и недовольства, относительно свободных от сомнений и разочарований. Высокие оценки: Энергичный, предприимчивый, бдительный, честолюбивый и многогранный; выглядящий человеком активным и продуктивным; ценящий работу и усилия сам по себе.
- Sa (самопринятие), для оценки таких факторов, как чувство собственного достоинства, самопринятие и способность к самостоятельным мыслям и поступкам. Высокие оценки: Интеллегентный, искренний, остроумный и эгоцентричный; способный легко и убедительно говорить; с присущей самоуверенностью и самонадеянностью
- Gi (хорошее впечатление) Для определения лиц, способных создавать о себе благоприятное впечатление и озабоченных тем, как к ним относятся другие люди.Высокие оценки: Проявляющий готовность к сотрудничеству, предприимчивый, открытый, общительный, сердечный и готовый оказать услугу; заботящийся о том, чтобы производить хорошее впечатление и выглядеть прилежным и упорным.
Ну и хватит. напомню, что в Вашей компании список значимых шкал и их вес может быть совсем другим, если вообще CPI позволит что-либо дифференциировать.
Удачи в отборе "pdtpl@
воскресенье, 13 марта 2016 г.
HR-аналитика. Анонс нового семинара
1-2 марта я провел очередной семинар "Аналитика для HR". Группа была очень серьезная, были представители от таких компаний как Ростелеком, Вымпелком, МТС, РайффайзенБанк, Ланит, Мостра-групп и другие, извините, если кого не упомянул.
У меня есть правило - постоянно обновлять семинар. В этот раз я уже даю логистическую регрессию (давал раньше, но в этот раз лог регрессия уже на рабочем уровне идет, воспринимается спокойно участниками). Дал анализ дожития. Впервые. Прошло с косяками, буду исправляться.
Еще раз спасибо всем участникам!
Новый семинар состоится 7-8 июля, анонс и регистрация по ссылке. Приглашаю
 Спасибо ДМК - пресс - дали мне несколько книг, которые я разыгрываю среди участников. Вот победители
Спасибо ДМК - пресс - дали мне несколько книг, которые я разыгрываю среди участников. Вот победители
От себя лично рекомендую книги по анализу данных от ДМК Пресс


У меня есть правило - постоянно обновлять семинар. В этот раз я уже даю логистическую регрессию (давал раньше, но в этот раз лог регрессия уже на рабочем уровне идет, воспринимается спокойно участниками). Дал анализ дожития. Впервые. Прошло с косяками, буду исправляться.
Еще раз спасибо всем участникам!
Новый семинар состоится 7-8 июля, анонс и регистрация по ссылке. Приглашаю

От себя лично рекомендую книги по анализу данных от ДМК Пресс


суббота, 12 марта 2016 г.
Прогноз цен на квартиры
Последнее время работы так много, что в блог не успеваю писать.
Решил выложить несколько картинок по прогнозу цен на квартиры, который я делал на реальных данных.
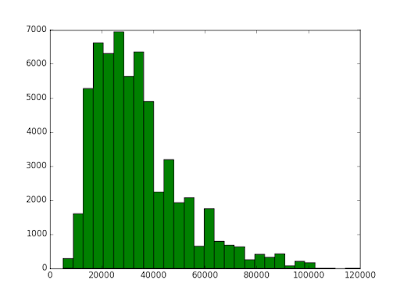
 Распределение цен на квартиры - очень логично выглядит, обращаю внимание, что это не Москва.
Распределение цен на квартиры - очень логично выглядит, обращаю внимание, что это не Москва.
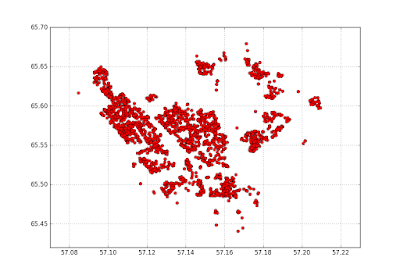 А это карта продаж: мы просто ставим по осям географические координаты и поучаем карты. Ну и плотность продаж.
А это карта продаж: мы просто ставим по осям географические координаты и поучаем карты. Ну и плотность продаж.
 Сглаживающая линия средней цены по времени.
Сглаживающая линия средней цены по времени.
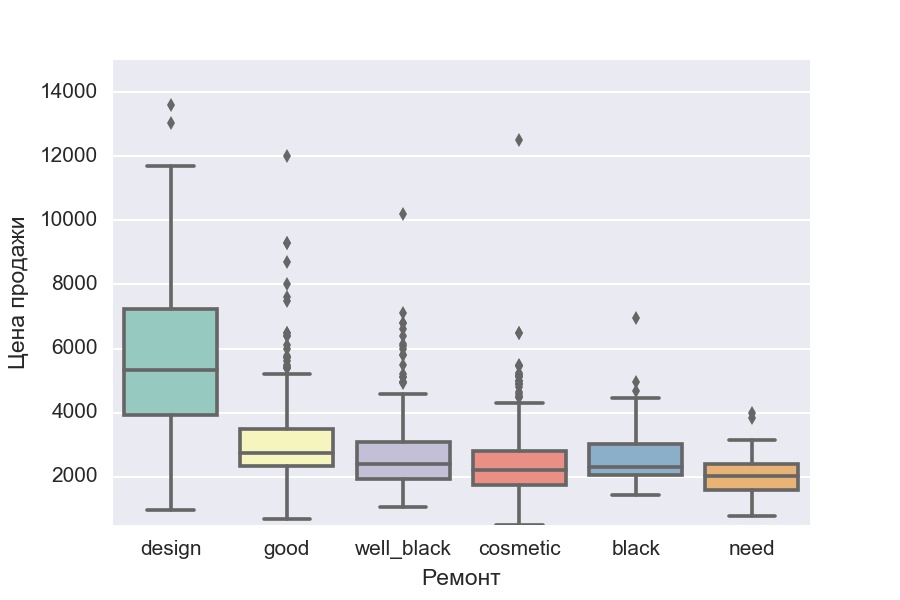
 Боксплот цен на квартиры в зависимости от типа ремонта.
Боксплот цен на квартиры в зависимости от типа ремонта.
 График связи цены и площади квартир, цветом обозначена комнатность. Заранее предупреждаю, я не отвечаю за качество данных, поэтому двух комнатные квартиры менее 30 кв м - вопрос не ко мне.
График связи цены и площади квартир, цветом обозначена комнатность. Заранее предупреждаю, я не отвечаю за качество данных, поэтому двух комнатные квартиры менее 30 кв м - вопрос не ко мне.
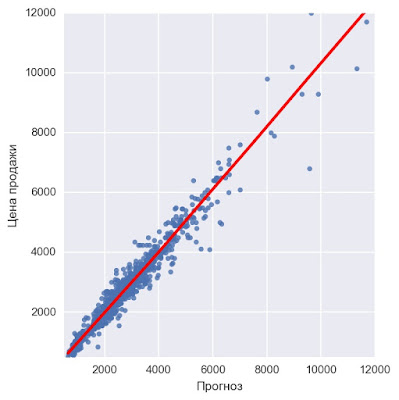 Финальная картина - по оси X прогнозные значения нашей модели, по оси Y реальные.
Финальная картина - по оси X прогнозные значения нашей модели, по оси Y реальные.
R^2 - 90 %
Решил выложить несколько картинок по прогнозу цен на квартиры, который я делал на реальных данных.




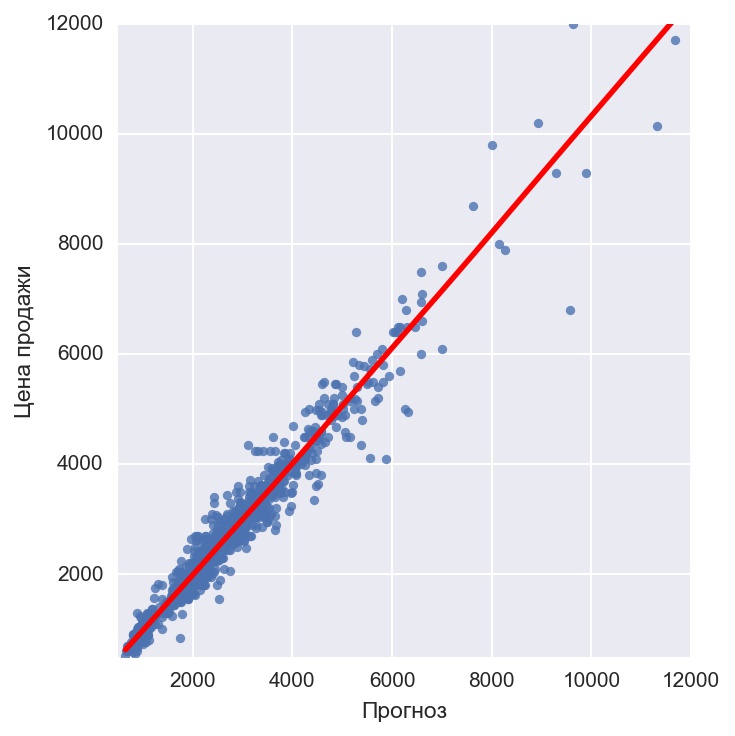
R^2 - 90 %
понедельник, 7 марта 2016 г.
Он-лайн курсы для hr-специалистов на курсере
Как-то поражает незнание hr-специалистов про возможности бесплатного он-лайн образования. Или неумения. Или нехотения. В общем, решил бороться с этой проблемой и накидать несколько курсов для самостоятельного изучения. Надеюсь, что такое Курсера, знают все. Для непосвященных коротко: платформа, где ведущие ВУЗы Мира бесплатно (не считая сертификации, т.е. если ы хотите сертификат, то платите) преподают различные курсы.Для hr специалистов можно порекомендовать такие курсы:
- Управление персоналом - серия из 4 курсов от университета Миннесоты: от рекрутмента до comp&ben
- Introduction to People Management - это курс с Edx.org (равноценный курсере). Курс ведут индусы.
- Стратегическое руководство и управление - 7 курсов от Иллинойсского университета
- Личное и командное лидерство - серия курсов университета Мичигана
- Управление конфликтами - серия курсов университета Калифорнии
- Прохождение собеседований и составление резюме на английском языке - 5 курсов от Мерилендского университета
- Руководство организацией - 6 курсов от Северо-западного университета
- People Analytics - курс Пенсильванского университета
- Introduction to People Analytics - наш, российский МИФИ ведет, но на английском.
- Career Success: essential skills for the workplace - 10 курсов для эффективных менеджеров от Калифорнийского университета
- Successful Negotiation: Essential Strategies and Skills - про переговоры от Мичигана
- Деловой английский - 5 курсов от Вашингтонского университета
- Human Resource Management and Leadership - специализация от Macquarie University / Университет Маккуори (Сидней, Австралия)
- Reputation Management in a Digital World - университет Curtin (Западная Австралия)
Я Вам еще не надоел?
Открываете главную страницу Курсеры и ищете то, что вам самим интересно.
Предупреждаю: сам я не учился на указанных курсах, мне моей аналитики более чем достаточно. Но обратную связь собираю, поэтому прошу писать свои отзывы в теме в группе на Линкедине в обсуждении Поделитесь: на каких курсах курсеры вы учились или прямо здесь, в комментах
Спасибо!
Понравился пост?
и Вы захотите выразить мне благодарность за интересные результаты, просто покликайте на директ рекламу ниже на странице - у вас это отнимет несколько секунд, а мне принесет немного денег.пятница, 4 марта 2016 г.
3 главных тренда в рекрутинге 2016 от Джона Салливана
В ноябре 2015 Салливан разродился статьей Recruiting Trends For 2016 And Their Supporting Best Practices, где выдал свое видение трендов. Я уже особо не слежу за ним - много воды. Но побывав на конференции HR metrix Russia, увидел, что проблемы те же.
Поэтому хотел как бы в качестве оппозиции нашим hr-ам три главных тренда от Салливана. Трендов на самом деле 12, но там много воды, переведу про три главных.
В известном всем фильме "Человек, который изменил все" главный герой говорит про 50 метров говна, под которыми находится его команда. Мы, казалось бы находимся под 500 метрами, но это только казалось бы. На самом деле у нас все просто замечательно. На Западе за последние 5 лет прошло две революции в рекрутинге, а мы, в России, сидим по прежнему нанефтяной игле: джоб сайты правят бал в подборе. Вы знаете хоть одну компанию в России, кто измеряет источники трафика кандидатов? На Западе таких несколько. О какой аналитике мы тогда вообще говорим? У нас нет базовых вещей, а мы обсуждаем стратегии"
Замечу только, что для России 50 % рефералов это как полететь на Луну.
Лучшие практики в этом месте
Ау, HR! Мы уже в XXI веке живем!
Поэтому хотел как бы в качестве оппозиции нашим hr-ам три главных тренда от Салливана. Трендов на самом деле 12, но там много воды, переведу про три главных.
Тренд №3 Используйте качество данных подбора, что понять, что работает, и тем увеличить ваше влияние на бизнес результаты
(Use quality of hire data to identify “what works” and to help quantify your business impacts). К бест практикам Салливан относит:- взаимодействие с финансовым департаментов компании с тем, чтобы отслеживать финансовые показатели рекрутинга;
- использование матмематической корреляции между показателями рекрутинга и бизнес показателями;
- Измерение % изменения качества работы вновь принятых, с тем, чтобы понять, как подбор на основе выявленных корреляций блияет на бизнес показатели;
- Измерение среднего дохода на одного работника после введения практик подбора;
- Измерение % подбора слабых работников и определение костов на них;
Тренд № 2. Подбор по рекомендациям даст более 50 % трафика
(Referrals will become 50 percent of all hiring … so you better get them right). На вышеуказанной конференции я выдал эмоциональную речь примерно такого содержания:В известном всем фильме "Человек, который изменил все" главный герой говорит про 50 метров говна, под которыми находится его команда. Мы, казалось бы находимся под 500 метрами, но это только казалось бы. На самом деле у нас все просто замечательно. На Западе за последние 5 лет прошло две революции в рекрутинге, а мы, в России, сидим по прежнему на
Замечу только, что для России 50 % рефералов это как полететь на Луну.
Тренд №1 Принятие решения о кандидате на основе данных
(Shifting to data-based decision-making in recruiting). Не знаю, как Салливан это посчитал, но он утверждает, что использование данных улучшает подбор на 25 % в сравнении, если бы вы пользовались просто интуицией (I estimate that compared to the normal intuitive decision, data-based decisions can be at least 25 percent better).Лучшие практики в этом месте
- Определение, какой источник дает лучших кандидатов;
- Определение, какие опросники и какие вопросы интервью позволяют прогнозировать трп перформасе;
- Вы поймете, какие работники дают классных рефералов, а какие нет;
- Поймете косты от не качественного найма;
- Поймете, кто из рекрутеров и линейных менеджеров ведут качественный подбор, а кто нет;
- Поймете "вес факторов" в их влиянии на успешность найма
Резюме
За два дня конференции HR metrix Russia я увидел только одну компанию, где работа с источниками трафика было принципиальным вопросом. Остальные компании (не считая кейсов по предиктивной аналитике, но мы их не считаем, поскольку практически все они были сделаны под моим влиянием: либо прямые клиенты, либо их работники посещали мои семинары) были как братья близнецы: мы измеряем текучесть, время закрытия вакансий, вовлеченность и т.п..Ау, HR! Мы уже в XXI веке живем!
четверг, 18 февраля 2016 г.
Прогноз предлагаемой зарплаты по описанию вакансии
В России уже такое делал ХХ, я не вижу в этом ничего интересного с т.з. продукта, но зато я вижу кучу возможностей для применения самого алгоритма.
Фишка в том, что в качестве независимых переменных у нас выступает текст. Не цифры, не категориальные переменные, а текст.
Вот пример того, как данные оформлены

Фишка в том, что в качестве независимых переменных у нас выступает текст. Не цифры, не категориальные переменные, а текст.
Вот пример того, как данные оформлены
FullDescription
|
LocationNormalized
|
ContractTime
|
SalaryNormalized
|
|
1
|
International Sales Manager London ****k ****...
|
London
|
permanent
|
33000
|
2
|
An ideal opportunity for an individual that ha...
|
London
|
permanent
|
50000
|
3
|
Online Content and Brand Manager// Luxury Reta...
|
South East London
|
permanent
|
40000
|
4
|
A great local marketleader is seeking a perman...
|
Dereham
|
permanent
|
22500
|
5
|
Registered Nurse / RGN Nursing Home for Young...
|
Sutton Coldfield
|
NaN
|
20355
|
В эту таблицу мы фактически закачали вакансии с job сайта.
- FullDescription - это описание вакансии
- LocationNormalized - место расположение вакансии
- ContractTime - постоянно или по контракту
- SalaryNormalized - уровень оплаты в английских рублях
Задача - спрогнозировать, какой будет оклад вакансии, если есть описание, а сам оклад не указан.

Это у нас распределение зависимой переменной - уровня оплаты.
Среднее значение - 34 000 р
Медиана - 30 000 р
Стандартное отклонение - 17 500 - ну здесь разброс очень большой, поскольку выбросы вправо.
Строим уравнение регрессии, где Y - это размер зарплаты, а независимые переменные - все остальные (описание, локация, контракт)

На этой картинке показана диаграмма прогнозных (ось X) и реальных (ось Y) значений зарплаты (всего в данных содержится 60 000 вакансий, поэтому такая большая плотность точек). Если бы мы давали 100 % точный прогноз, у нас была бы прямая линия на графике. Но мы, конечно же, не даем 100 % правильного прогноза. Показатели качества модели у нас такие:
- R^2 - 0, 72
- Средняя ошибка - 9 100 английских рублей.
Я бы оценил это как средний уровень качества прогноза.Но понятно, что с моделью можно еще играться с т.з. повышения качества.
В качестве фантазии: где бы вы хотели применить анализ текста?
воскресенье, 14 февраля 2016 г.
Контрольная карта Шухарта в управлении hr бизнес процессами (на основе текучести персонала)
Приведу достаточно простой пример контрольной карты Шухарта на основе процесса управления текучестью персонала.
 У нас есть данные о текучести персонала по месяцам (на картинке ось X - 1 январь, 12 - декабрь, и по оси Y - количество уволившихся). У вас в компании могут быть данные за бОльшее количество лет, вы можете проанализировать бОльшее количество данных.
У нас есть данные о текучести персонала по месяцам (на картинке ось X - 1 январь, 12 - декабрь, и по оси Y - количество уволившихся). У вас в компании могут быть данные за бОльшее количество лет, вы можете проанализировать бОльшее количество данных.
На данной картинке задача вырисовывается просто: можно ли бить в набат по апрельским данным?
В excel таблица будет выглядеть так

На данной картинке задача вырисовывается просто: можно ли бить в набат по апрельским данным?
В excel таблица будет выглядеть так
январь
|
9
|
февраль
|
7
|
март
|
11
|
апрель
|
19
|
май
|
9
|
июнь
|
9
|
июль
|
9
|
август
|
13
|
сентябрь
|
13
|
октябрь
|
13
|
ноябрь
|
12
|
декабрь
|
14
|
Считаем среднее и стандартное отклонение
Среднее = 11, 5
Стандартное отклонение = 3, 23
Вспоминаем нормальное распределение

У нас + два стандартных отклонения дают более 95 % событий.
Считаем для нашего кейса
11, 5 + 3, 23 * 2 = 17, 96
17, 96 (давайте возьмем 18) - порог, выше которого нужно бежать вприпрыжку - в смысле думать, а с чего бы это.
В апреле уволилось 19 человек. Делаем вывод, что отклонение значимое для данного набора данных, следовательно за увольнениями в апреле стоит какая - то причина, которую надо выяснять. Ну а дальше уже управленческие действия - профилактика, усиление эффекта и т.п..
В идеале стоит нарисовать картинку в excel, где значения увольнений показаны линией, а на графике еще три прямые:
- 11, 5 - центральная линия,
- 17, 96 - верхняя линия / граница
- 5,05 - нижняя линия / граница.
выход на рамки 5 и 18 - красная лампочка. Рисовать не буду, пусть будет вам домашнее задание.
понедельник, 8 февраля 2016 г.
Семинар - практикум "Аналитика для HR", 17-18 июня, Владивосток
Анонсирую свой семинар во Владивостоке 17-18 июня. Для подачи заявки воспользуйтесь контактами менеджера внизу страницы.
Формат
Вводная
Если вас тошнит от формул, вычислений, Excel – этот мастер-класс вам противопоказан.
О семинаре
Посчитать корреляцию сейчас многие умеют. Посчитать,
сколько стоит корреляция в бизнесе - единицы. На семинаре я учу, как корреляцию
превращать в доходы компании.
Семинар про управление HR-бизнес процессами: бизнес
ставит проблему, мы ее форматируем, моделируем, оцифровываем данные, выявляем
ключевые драйверы, интерпретируем и ... управляем... На Западе это обозначается как BigData в HR, я называю
просто - Аналитика для HR
Формат
Мастер-класс. Участники в начале семинара получают
раздаточный материал в электронном виде. Семинар представляет из себя
последовательное решение в рабочем файле excel кейсов, объединенных логикой
подачи материала. 90 % кейсов взяты из реальной практики, чаще всего от
участников прошлых семинаров.
Для кого
Семинар
будет полезен в первую очередь тем, кто хотел бы управлять эффективностью и
текучестью персонала: выявлять на этапе подбора наиболее эффективных
кандидатов, кандидатов, склонных к быстрому уходу из компании, оценивать
эффективность обучения и, в более широком смысле, эффективность практик
компании (как, пример, оценить эффективность программы рекомендательного
рекрутинга с т.з. повышения эффективности и снижения текучести персонал, как
оценить эффективность рекламной компании по привлечению кандидатов, как оценить
эффективность обучения и т.д. и т.п.. ) Резюме:
для тех, кто хочет показывать бизнесу, как HR влияет на бизнес показатели.
Программа семинара:
Вводная
- Понятие
hr-аналитики и области ее применения.
- Примеры
успешного внедрения аналитик: Западная и российская практика.
- Правила
чтения отчетов (обзоров зарплат, исследований рынка труда, бечмаркинговых
отчетов) и практическое их применение.
- Базовые
термины аналитики и статистики.
- Построение
системы сбора данных в компании
Моделирование в аналитике
- Постановка
проблемы: проблему ставит бизнес
- Переводим
на свой язык: цели, модели и форматы решаемых задач
- Гипотезы
- "Оцифровка"
данных
- Типы
данных
- Представление
и визуализация данных
Обработка и анализ
данных
- Вычисления
в excel (формулы, сводные таблицы, "Пакет анализа")
- Статистические
методы обработки информации (матстатистика для HR)
- Основные
статистические критерии и методы
- Прогноз,
точность модели
- Программы
обработки данных: excel, SPSS
Условия участия:
НАЛИЧИЕ СВОЕГО НОУТБУКА с программой EXCEL (офис
2010-2016) под windows
Предупреждение, warning
und achtung!
Если вас тошнит от формул, вычислений, Excel – этот мастер-класс вам противопоказан.
Чего не будет:
Я не
буду говорить, какие HR-метрики "лучше". Будем учиться применять
анализ для понимания того, какие показатели адекватны в какой ситуации.
Я не буду учить строить отчеты: сводные таблицы вам в помощь. Семинар не про построение отчетов, он про анализ информации.
Я не буду учить строить диаграммы: а только, в каком случае какой способ визуализации более релевантен.
Я не буду учить строить отчеты: сводные таблицы вам в помощь. Семинар не про построение отчетов, он про анализ информации.
Я не буду учить строить диаграммы: а только, в каком случае какой способ визуализации более релевантен.
Стоимость участия:
18000 рублей. В стоимость включены кофе-паузы и обеды.
По окончании программы выдается Сертификат.
Лицензия на право ведения образовательной
деятельности № 425 от 18.07.2011 г.
Руководитель
проекта Урманова Наталья,
сот.
8-904-629-02-64,
8(423)299-02-64
воскресенье, 7 февраля 2016 г.
О границах принятия решения по кандидату
Хочу познакомить с одним интересным термином, еще одной интересной техникой и проблемой в отборе персонала (настоящей проблемой, а не выдуманной)
В основе поста уже часто приводимый пример - Отбираем "звезд" на этапе подбора с помощью тестов.
Вводная: 87 работников экспертным путем поделены на "звезд" (эффективных) и "не звезд". Все они при приеме на работу проходили тестирование. Проведенный анализ выявил две шкалы, которые позволяли прогнозировать, будет ли кандидат "звездой" или "не звездой".
Визуально это выглядит так
"Звезды" - зеленые, а "не звезды" - красные. Заметно, что звезды не имеют показателей выше 50 баллов, по шкале Fx, а вот со шкалой Sp все сложнее. Здесь нет однозначного решения. Можно провести границу по 50 баллам, но тогда мы в "звезды" захватим не звезд... Если по 60 баллам, то многих "звезд" просто выкинем. Это проблема выбора границы.
Машинка может подсказать нам решение - Алгоритмы выявления звезд: дерево решения в R и Python. Вот каковы границы принятия решения, подсказанные машинкой
 В данном случае машинка определяет звезд по границам:
В данном случае машинка определяет звезд по границам:
Но точность модели при таких границах 83 % (т.е. мы в 83 % "попадаем" с прогнозом), а со звездами вообще проблема: у нас всего 29 "звезд", из них мы "звездами" отбираем 18, т.е. 62 %. Фактически каждую третью "звезду" мы пропускаем. Это прискорбно.
Можно поменять границы, но это уже проблема компромисса.
Машинка по нашей просьбе может нарисовать гибкие границы
Это тот же самый рисунок, где цвет обозначает "звезд" - синим и "не звезд" - красным. И границы, как видно, гибкие. При такой постановке задачи точность принятия решения достигает 90 %. Просто невероятная точность на сегодняшний день для наших компаний. Ну если не верить бреду тех консалтеров про 95 % точность. Напомню, что в Google приближаются к точности в 86 % см. Про качество подбора персонала на основе интервью.
И напомню: границы рисует машинка, а не человек, не пытайтесь повторить трюк)))
Удачи вам в отборе персонала)
И обращайтесь: я предоставляю услугу Прогноз успешности кандидатов на основе тестов
В основе поста уже часто приводимый пример - Отбираем "звезд" на этапе подбора с помощью тестов.
Вводная: 87 работников экспертным путем поделены на "звезд" (эффективных) и "не звезд". Все они при приеме на работу проходили тестирование. Проведенный анализ выявил две шкалы, которые позволяли прогнозировать, будет ли кандидат "звездой" или "не звездой".
Визуально это выглядит так
Машинка может подсказать нам решение - Алгоритмы выявления звезд: дерево решения в R и Python. Вот каковы границы принятия решения, подсказанные машинкой
- Sp - 56 баллов;
- Fx - 44 баллов.
Но точность модели при таких границах 83 % (т.е. мы в 83 % "попадаем" с прогнозом), а со звездами вообще проблема: у нас всего 29 "звезд", из них мы "звездами" отбираем 18, т.е. 62 %. Фактически каждую третью "звезду" мы пропускаем. Это прискорбно.
Можно поменять границы, но это уже проблема компромисса.
Гибкие границы
Но кто сказал, что границы принятия решения должны быть прямыми?Машинка по нашей просьбе может нарисовать гибкие границы

И напомню: границы рисует машинка, а не человек, не пытайтесь повторить трюк)))
Удачи вам в отборе персонала)
И обращайтесь: я предоставляю услугу Прогноз успешности кандидатов на основе тестов
суббота, 6 февраля 2016 г.
HR прогнозы 2016 от Берзина
Самые полноценные прогнозы и тренды в HR дает Джош Берзин, это единственный западный спец, за кем я слежу системно, а не от случая к случаю.

Я прослушал его ебинар по прогнозам и даю слайдшоу с вебинара. Как мне кажется, слайды дают общее представление о докладе Берзина.
Понятно, что я публикую не все слайды часового вебинара, а только или с интересными данными, на мой взгляд, или концептуальные слайды.
Некоторые слайды мне, с т.з. аналитики, кажутся наивными, но судите сами
Адженда

четверг, 4 февраля 2016 г.
Алгоритмы выявления звезд: дерево решения в R и Python
Прохожу курс Высшей Школы Экономики по машинному обучению, где основной программой анализа является Python.
Хочу показать разницу в алгоритме Decision Trees.
Вот эта задача Отбираем "звезд" на этапе подбора с помощью тестов. Суть проста: при входе в компанию кандидаты проходили тестирование, спустя время их экспертным методом причисляли к звездам или не звездам. И на основе классификации создавали алгоритм отбора.
Я уверен, что со временем многие компании создадут свои подобные алгоритмы выявления звезд.
Обращайтесь, кстати, Прогноз успешности кандидатов на основе тестов
Сверху алгоритм Python, снизу - R. Обратите внимание, что шкалы отбора выбраны программы выбраны одинаковые - Sp и Fx, граница Sp - 56, только Python больше или равно 56, а R больше 56, а граница Fx 50 и 44.
В R цифры следующее обозначает: если кандидат набирает менее 56 баллов по шкале Sp, то с вероятностью 90 % он не звезда, если он набирает более 56 баллов и менее 50 по шкале Fx, то с вероятностью 85 % он будет звездой.
В Python все похоже: сначала идет обозначение границы, потом критерий gini (это специфичный критерий, показывающий способность границы делить классы), samples - количество кандидатов в данной точке, value - количество звезд / не звезд в данной точке.
Т.е. если кандидат показывает больше 56 баллов по Sp и меньше или равно 44 по Fx, то вы с вероятностью 86 % звезда. Вероятность так считается: 18 / 21 = 85, 7 %

Хочу показать разницу в алгоритме Decision Trees.
Вот эта задача Отбираем "звезд" на этапе подбора с помощью тестов. Суть проста: при входе в компанию кандидаты проходили тестирование, спустя время их экспертным методом причисляли к звездам или не звездам. И на основе классификации создавали алгоритм отбора.
Я уверен, что со временем многие компании создадут свои подобные алгоритмы выявления звезд.
Обращайтесь, кстати, Прогноз успешности кандидатов на основе тестов

В R цифры следующее обозначает: если кандидат набирает менее 56 баллов по шкале Sp, то с вероятностью 90 % он не звезда, если он набирает более 56 баллов и менее 50 по шкале Fx, то с вероятностью 85 % он будет звездой.
В Python все похоже: сначала идет обозначение границы, потом критерий gini (это специфичный критерий, показывающий способность границы делить классы), samples - количество кандидатов в данной точке, value - количество звезд / не звезд в данной точке.
Т.е. если кандидат показывает больше 56 баллов по Sp и меньше или равно 44 по Fx, то вы с вероятностью 86 % звезда. Вероятность так считается: 18 / 21 = 85, 7 %

понедельник, 1 февраля 2016 г.
Нормы текучести IT специалистов
Ну а почему бы и нет.
Данный пост построен на основе двух моих исследований
Исследование времени поиска работы
Ключевые факторы удержания и текучести персонала
(примите участие в опросах - оба действующие)
Чтобы сделать результаты более человечными, нужно сделать следующее:
 Как читать такой тип диаграммы - Анализ и визуализация дожития: чем HR похож на медиков.
Как читать такой тип диаграммы - Анализ и визуализация дожития: чем HR похож на медиков.
25 50 75
11.2 30.0 55.2
$lower
7.8 24 48
$upper
16.4 38.7 79.4
Эти циферки обозначают следующее:
25, 50, 75 - это квартили, lower - нижний доверительный интервал, upper - верхний, а показатели - стаж в месяцах.
Если совсем просто, то средний IT спец в среднем дорабатывает до 30 месяцев, или точнее, средний "срок жизни" попадает в промежуток 24 и 38 месяцев.
Большой разброс? Ну я уже задолбался уговаривать участвовать в исследовании.
Или вот такой результат:
Быстрее всех бегут первогодки: 25 % новичков сбегают из компании;
Второгодки бегут меньше: примерно 20 %;
А вот на третий год бегут всего примерно 10 %
Если вам, все таки интересны результаты - напишите коммент, что вам это нужно, я буду продолжать.
Данный пост построен на основе двух моих исследований
Исследование времени поиска работы
Ключевые факторы удержания и текучести персонала
(примите участие в опросах - оба действующие)
Результаты
Всего в выборке 194 IT специалиста. Обращаю ваше внимание: среди этих 194 специалистов айтишники России, Украины, Беларуси, всех уровней позиций - от джуниора до первого уровня, всех отраслей. Поэтому я показываю среднюю температуру по больнице.Чтобы сделать результаты более человечными, нужно сделать следующее:
- указать мне, какие срезы интересно посмотреть (по отраслям, по уровню позиции, по странам);
- пригласить знакомых айтишников принять участие в опросах (см. выше)
- а можно также указать те позиции, которые вам интересны: я имею ввиду, что не только нормы текучести IT спецов могут быть интересны

- По оси X - число месяцев стажа
- По оси Y - вероятность, что работник доработает до этого момента стажа в компании.
Данные
$quantile25 50 75
11.2 30.0 55.2
$lower
7.8 24 48
$upper
16.4 38.7 79.4
Эти циферки обозначают следующее:
25, 50, 75 - это квартили, lower - нижний доверительный интервал, upper - верхний, а показатели - стаж в месяцах.
Если совсем просто, то средний IT спец в среднем дорабатывает до 30 месяцев, или точнее, средний "срок жизни" попадает в промежуток 24 и 38 месяцев.
Большой разброс? Ну я уже задолбался уговаривать участвовать в исследовании.
Или вот такой результат:
Быстрее всех бегут первогодки: 25 % новичков сбегают из компании;
Второгодки бегут меньше: примерно 20 %;
А вот на третий год бегут всего примерно 10 %
Если вам, все таки интересны результаты - напишите коммент, что вам это нужно, я буду продолжать.
Обращение
Коллеги, опрос проводится на некоммерческой основе, у меня нет спонсоров, я трачу много своего времени, поэтому, если Вы захотите выразить мне благодарность за интересные результаты, вы можете перевести небольшую сумму мне на Яндекс кошелек (кликните по кнопке Перевести)
или сделать перевод на карту Сбербанка,
Номер карты 676 280 38 921 538 46 57 - укажите "за результаты исследования".
Или просто покликайте на директ рекламу ниже на странице - у вас это отнимет несколько секунд, а мне принесет немного денег.
спасибо!
Подписаться на:
Сообщения (Atom)