В России уже такое делал ХХ, я не вижу в этом ничего интересного с т.з. продукта, но зато я вижу кучу возможностей для применения самого алгоритма.
Фишка в том, что в качестве независимых переменных у нас выступает текст. Не цифры, не категориальные переменные, а текст.
Вот пример того, как данные оформлены

Фишка в том, что в качестве независимых переменных у нас выступает текст. Не цифры, не категориальные переменные, а текст.
Вот пример того, как данные оформлены
FullDescription
|
LocationNormalized
|
ContractTime
|
SalaryNormalized
|
|
1
|
International Sales Manager London ****k ****...
|
London
|
permanent
|
33000
|
2
|
An ideal opportunity for an individual that ha...
|
London
|
permanent
|
50000
|
3
|
Online Content and Brand Manager// Luxury Reta...
|
South East London
|
permanent
|
40000
|
4
|
A great local marketleader is seeking a perman...
|
Dereham
|
permanent
|
22500
|
5
|
Registered Nurse / RGN Nursing Home for Young...
|
Sutton Coldfield
|
NaN
|
20355
|
В эту таблицу мы фактически закачали вакансии с job сайта.
- FullDescription - это описание вакансии
- LocationNormalized - место расположение вакансии
- ContractTime - постоянно или по контракту
- SalaryNormalized - уровень оплаты в английских рублях
Задача - спрогнозировать, какой будет оклад вакансии, если есть описание, а сам оклад не указан.

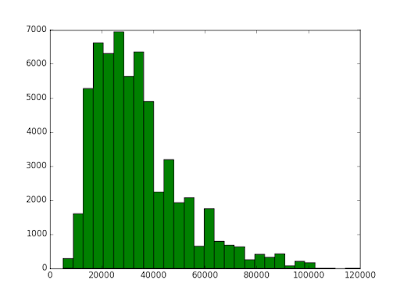
Это у нас распределение зависимой переменной - уровня оплаты.
Среднее значение - 34 000 р
Медиана - 30 000 р
Стандартное отклонение - 17 500 - ну здесь разброс очень большой, поскольку выбросы вправо.
Строим уравнение регрессии, где Y - это размер зарплаты, а независимые переменные - все остальные (описание, локация, контракт)

На этой картинке показана диаграмма прогнозных (ось X) и реальных (ось Y) значений зарплаты (всего в данных содержится 60 000 вакансий, поэтому такая большая плотность точек). Если бы мы давали 100 % точный прогноз, у нас была бы прямая линия на графике. Но мы, конечно же, не даем 100 % правильного прогноза. Показатели качества модели у нас такие:
- R^2 - 0, 72
- Средняя ошибка - 9 100 английских рублей.
Я бы оценил это как средний уровень качества прогноза.Но понятно, что с моделью можно еще играться с т.з. повышения качества.
В качестве фантазии: где бы вы хотели применить анализ текста?
Для анализа присылаемых резюме. Например мы имеем n успешных работников, которые в свое время нам направили свое резюме. Для начала попытаться составить некое "универсальное резюме" успешного кандидата. А потом анализировать текст в резюме новых кандидатов на схожесть с нашим "универсальным" резюме.
ОтветитьУдалитьправильно, но можно еще проще)
УдалитьКак? Если без тестов, а только на основании текста в направленном резюме?
Удалить