Прелесть данного кейса в том, что я впервые в качестве предиктора данные не только самих работников, но данные руководителя
Всего были использованы такие данные в модели:
Далее факторы идут в вперемешку (хотя менее значимы факторы пола, соотношения полов руководитель / подчиненный) , но в качестве главного вывода исследования можно сказать, что результаты руководителя влияют не меньше, чем результаты самого работника.
Звездоболам не рекомендую открывать рот и говорить, что это очевидно.
Подскажите, как можно поступить в данном случае? Кластерный анализ?
Маловато, не спорю.
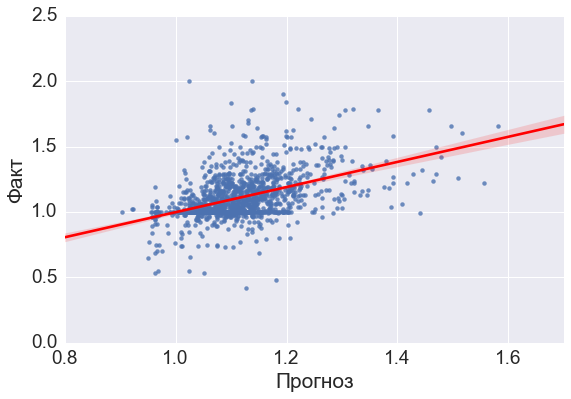
По оси X - прогнозные значения;
По оси Y - фактические
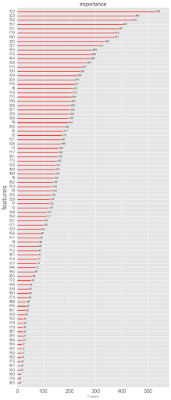
И посмотрите, какое количество факторов было в модели
 * можно увеличить картинку, кликнув по ней
* можно увеличить картинку, кликнув по ней
Всего были использованы такие данные в модели:
- Стаж работы в должности
- Данные подразделения, должности, региона и т.е..
- Пол, возраст сотрудника
- Пол руководителя, соотношение полов руководитель / подчиненный;
- Тест интеллекта сотрудника;
- Личностный тест сотрудника;
- Тест интеллекта руководителя;
- Личностный тест руководителя.
Результаты
Практически все указанные факторы внесли свой в точность модели (см. на самой нижний картинке значимость факторов - не расшифровываю названия, поскольку кейс реальный, соблюдаю конфиденциальнсоть). На первом месте по значимости стаж работы. Т.е. рост эффективности в первую очередь определяется стажем.Далее факторы идут в вперемешку (хотя менее значимы факторы пола, соотношения полов руководитель / подчиненный) , но в качестве главного вывода исследования можно сказать, что результаты руководителя влияют не меньше, чем результаты самого работника.
Звездоболам не рекомендую открывать рот и говорить, что это очевидно.
Вопрос
В этом месте я обращаюсь за помощью к профи: я в качестве предиктора использовал просто шкалы теста, но подозреваю, что важным является не просто наличие или отсутствие того или иного качества у руководителя или подчиненного, а взаимодействие этих качеств у руководителя и подчиненного (на примере пола я показываю, что мы смотрим не просто пол руководителя или пол подчиненного, а взаимодействие полов, т.е. их возможные сочетания: ММ, МЖ, ЖМ, ЖЖ). Т.е. говоря математически, мы должны проверить гипотезы об интеракции факторов. Но просто перебор шкалы со шкалой чересчур трудоемкая работа: даже ели бы у нас был Big5 у руководителя и подчиненного, то количество возможных сочетаний будет 25, а у нас не Big5, поэтому количество проверяемых гипотез больше в десятки раз.Подскажите, как можно поступить в данном случае? Кластерный анализ?
Картинки
Ну и без того, у нас модель получилась выше плинтуса. Я тренировал модель на RMSE - отклонении прогнозного значения от фактического, но поскольку без масштаба будет непонятно, то даю R^2. Он в нашей модели получился 0, 33.Маловато, не спорю.
В этом месте вы выходим на один важный вопрос, который я еще в дискурсиях не встречал ни разу: какова в принципе возможна прогнозируемая точность на основе входных данных? Поскольку на эффективность влияет куча других, динамичных факторов, таких как ситуация на рынке, отношения в коллективе, маркетинговая политика компании и другие политики, мотивация и обучения персонала и т.п..На картинке точность так выглядит

По оси X - прогнозные значения;
По оси Y - фактические
И посмотрите, какое количество факторов было в модели

Понравился пост?
покликайте на директ рекламу ниже на странице - у вас это отнимет несколько секунд, а мне принесет немного денег.
спасибо!
Может быть для проверки гипотезы об интеракции факторов попробовать канонический и/или дискриминантный анализ?
ОтветитьУдалитьэто как? поясните
Удалить