Докладываю первые результаты нашего Исследования времени поиска работы (даю ссылку, чтобы заинтересованные поучаствовали в опросе с тем, чтобы повысить качество результатов). У нас большая проблема: для обсчета было принято 167 голосов респондентов, из которых 77 нашли работу на момент заполнения опросника, а остальные находились в поиске.
И ответ на вопрос
 На картинке:
На картинке:
Специалисты, конечно, скажут и будут првы, что диаграмма не корректна, что показывать тренд на ненормированных данных неправильно, но я решил пренебречь корректностью в пользу наглядности, а для специалистов показать уравнение регрессии
Call:
coxph(formula = Surv(time, event) ~ log(ZP), data = q)
n= 167, number of events= 77
coef exp(coef) se(coef) z Pr(>|z|)
log(ZP) -0.7543 0.4703 0.1535 -4.913 8.97e-07 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
exp(coef) exp(-coef) lower .95 upper .95
log(ZP) 0.4703 2.126 0.3481 0.6355
Concordance= 0.694 (se = 0.037 )
Rsquare= 0.129 (max possible= 0.98 )
Likelihood ratio test= 23.07 on 1 df, p=1.565e-06
Wald test = 24.14 on 1 df, p=8.97e-07
Score (logrank) test = 25.11 on 1 df, p=5.405e-07
Обратите внимание, что я в формуле использую LOG зарплаты с тем, чтобы нормализовать переменную. и объясненная дисперсия вполне себе даже ничего.

Показатели такие
Call:
coxph(formula = Surv(time, event) ~ log(stag), data = q1)
n= 163, number of events= 75
(2 observations deleted due to missingness)
coef exp(coef) se(coef) z Pr(>|z|)
log(stag) -0.2338 0.7916 0.1123 -2.081 0.0374 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
exp(coef) exp(-coef) lower .95 upper .95
log(stag) 0.7916 1.263 0.6352 0.9865
Concordance= 0.565 (se = 0.038 )
Rsquare= 0.026 (max possible= 0.98 )
Likelihood ratio test= 4.33 on 1 df, p=0.03747
Wald test = 4.33 on 1 df, p=0.03741
Score (logrank) test = 4.37 on 1 df, p=0.03658
Объясненная дисперсия очень небольшая - всего 2,6 %, а значимость коэффициента 0, 037.
 в обозначениях, думаю, все в порядке, уравнение регрессии значимо и дает 6 % объясненной дисперсии.
в обозначениях, думаю, все в порядке, уравнение регрессии значимо и дает 6 % объясненной дисперсии.
А теперь мы в одном уравнении объединяем возраст и стаж и получаем
coef exp(coef) se(coef) z Pr(>|z|)
Год.Рождения 0.04163 1.04251 0.01602 2.598 0.00939 **
log(stag) -0.16068 0.85157 0.12011 -1.338 0.18099
Приглашаю поучаствовать! Исследование времени поиска работы
И главное: потренируйтесь в гипотезах: напишите, как вы считаете, какие факторы (из используемых в опросе) могут влиять на продолжительность поиска работы
Отсюда я вижу два важных вывода:
Как зарплата влияет на время поиска работы
В HR-квест я задал вопрос. Как вы считаете, какое из утверждений корректно:- Специалисты с более высокой зарплатой БЫСТРЕЕ выходят на новое место работы при условии, что инициатором увольнения с последнего места работы был работодатель
- Специалисты с более высокой зарплатой ДОЛЬШЕ ищут новую работу при условии, что инициатором увольнения с последнего места работы был работодатель
- размер оплаты не влияет на срок поиска работы
И ответ на вопрос

- по оси X - ZP - уровень зарплаты респондента на последнем месте работы (в тысячах рублей);
- по оси Y - time - время поиска работы в днях;
- зеленые точки - те специалисты, что вышли на новое место работы (нашли работу);
- красные - еще находятся в поиске (не нашли работу).
- красная и зеленая линии - линии тренда, которые показывают, что чем выше зарплата, том дольше человек ищет работу.
Специалисты, конечно, скажут и будут првы, что диаграмма не корректна, что показывать тренд на ненормированных данных неправильно, но я решил пренебречь корректностью в пользу наглядности, а для специалистов показать уравнение регрессии
Call:
coxph(formula = Surv(time, event) ~ log(ZP), data = q)
n= 167, number of events= 77
coef exp(coef) se(coef) z Pr(>|z|)
log(ZP) -0.7543 0.4703 0.1535 -4.913 8.97e-07 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
exp(coef) exp(-coef) lower .95 upper .95
log(ZP) 0.4703 2.126 0.3481 0.6355
Concordance= 0.694 (se = 0.037 )
Rsquare= 0.129 (max possible= 0.98 )
Likelihood ratio test= 23.07 on 1 df, p=1.565e-06
Wald test = 24.14 on 1 df, p=8.97e-07
Score (logrank) test = 25.11 on 1 df, p=5.405e-07
Обратите внимание, что я в формуле использую LOG зарплаты с тем, чтобы нормализовать переменную. и объясненная дисперсия вполне себе даже ничего.
Как стаж работы влияет на продолжительность поиска работы
Имеется ввиду стаж работы на последнем месте работы. И здесь картина не столь очевидная
- По оси X - стаж работы на предыдущем месте работы в годах;
- По оси Y - время поиска работы в годах;
- зеленые точки - те специалисты, что вышли на новое место работы (нашли работу);
- красные - еще находятся в поиске (не нашли работу).
- красная и зеленая линии - линии тренда, которые показывают, что чем выше зарплата, том дольше человек ищет работу.
Показатели такие
Call:
coxph(formula = Surv(time, event) ~ log(stag), data = q1)
n= 163, number of events= 75
(2 observations deleted due to missingness)
coef exp(coef) se(coef) z Pr(>|z|)
log(stag) -0.2338 0.7916 0.1123 -2.081 0.0374 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
exp(coef) exp(-coef) lower .95 upper .95
log(stag) 0.7916 1.263 0.6352 0.9865
Concordance= 0.565 (se = 0.038 )
Rsquare= 0.026 (max possible= 0.98 )
Likelihood ratio test= 4.33 on 1 df, p=0.03747
Wald test = 4.33 on 1 df, p=0.03741
Score (logrank) test = 4.37 on 1 df, p=0.03658
Объясненная дисперсия очень небольшая - всего 2,6 %, а значимость коэффициента 0, 037.
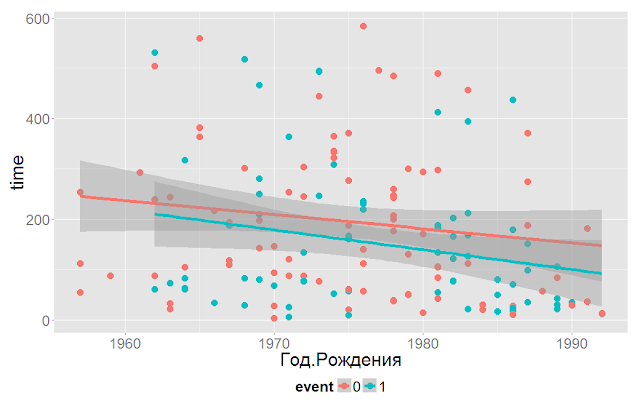
Про возраст
И еще потерпите немного
А теперь мы в одном уравнении объединяем возраст и стаж и получаем
coef exp(coef) se(coef) z Pr(>|z|)
Год.Рождения 0.04163 1.04251 0.01602 2.598 0.00939 **
log(stag) -0.16068 0.85157 0.12011 -1.338 0.18099
Т.е. переводя с русского на русский, мы говорим, что стаж работы на предыдущем месте работы не влияет на продолжительность поиска работы. Влияет возраст кандидата. И чем старше кандидат, тем дольше он ищет работу.
Приглашаю поучаствовать! Исследование времени поиска работы
И главное: потренируйтесь в гипотезах: напишите, как вы считаете, какие факторы (из используемых в опросе) могут влиять на продолжительность поиска работы
Резюме
Самое забавное возникает, когда мы объединим вместе зарплату, стаж и возраст. В этом случае значимой остается только переменная "зарплата".Отсюда я вижу два важных вывода:
- возраст сам по себе не является помехой в поиске работы
- за всеми этими переменными стоят скорее всего зарплатные и карьерные ожидания: чем дольше специалист работает в компании, тем он выше поднимается по карьерной лестнице, тем дольше ищет подходящую работу
Добрый день! Спасибо за интересные выкладки. Было всего 167 анкет? Разве этого достаточно для репрезентативной выборки? Удивлен, что стаж работы на последнем месте не влияет на то, как быстро ты находишь новую работу... Интересно было бы еще исследовать, как занятость на момент поиска работы влияет на привлекательность твоего резюме. Мой опыт показывает, что если ты работаешь, то тебя охотнее позовут на интервью, чем кандидата, который на момент обращения к работодателю не работает… И чем дальше от момента увольнения, тем менее интересен ты для работодателя. И неоднократно приходилось слышать мнение, что длительная безработица – это повод «прогнуть» тебя по зарплате… С уважением, Андрей Букин.
ОтветитьУдалитьАндрей, а что значит репрезентативная выборка?
УдалитьЧто она должна репрезентировать?
По поводу ваших - гипотез - услышал, часть можно проверить. Например срок поиска работы теми, кто еще работает.
Хотите увеличить репрезентативность - поучаствуйте в опросе
Я лично неоднократно слышала от руководителей отделов, отклики по кандидатам: "Этого я брать не хочу у него маленький стаж работы и вот этого, ну и что, что он раньше имел такой опыт, на сегодняшний день он 4 месяца без работы".
ОтветитьУдалитьВ связи с кризисом, как по мне, ситуация в этом плане несколько ухудшилась. Возможно, стоит увеличить количество опрошенных?
а вы лично поучаствовали?
УдалитьА своих коллег пригласили?
особенно тех, кто так говорит про кандидатов?
по поводу данного поста мне не менее десятка человек про количество респондентов написало, а проголосовало после моего обращения знаете сколько, ага, всего двое
УдалитьРепрезентативности (есть хорошее русское слово у академика Чупрова для этого термина -"представительность" )выборки, можно на мой взгляд , добиться простой сортировкой данных опроса по отраслям или по профессиям.
ОтветитьУдалитьРоман.
ура) спасибо за здравый коммент
Удалитьчтобы добиться внятной представительности, нам нужно порядка 3 000 респондентов, сейчас чуть более 500
и нам нужно ответить на вопрос, влияют ли те или иные факторы на поиск работы
единственный bais. который не смогу победить - в опросе наверняка чаще участвуют те, у кого проблема с поиском...
Конечно могу ошибаться, но с таким R^2 сложно говорить про объясняющую "красная и зеленая линии - линии тренда, которые показывают, что чем выше зарплата, том дольше человек ищет работу" . Плотность коррелографа низкая для поиска взаимосвязи. Может имеет смыл построит дендрограмму, для определения групп, а потом уже делать график поиска взаимосвязи в группах, разделённых по "яркому" признаку? На первом графике есть явное скопление внизу.
ОтветитьУдалитьЭто же не линейная регрессия, Юрий
Удалитьдавайте еще раз.
график и уравнение регрессии - разного свойства.
график линейный, а уравнение - нет
и красные и зеленые точки я дал именно потому, что зеленые - это закрытые события - человек нашел работу, а красные - незакрытые - т.е. человек еще в поиске
поэтому для красных в принципе линейное уравнение не подходит